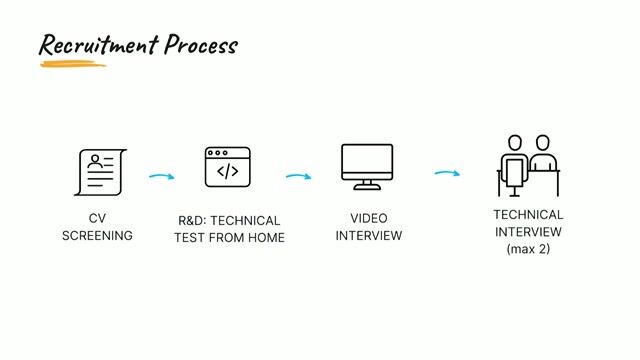
DATA SCIENTIST
Role details
Job location
Tech stack
Job description
ContexteNotre client a misé sur une plateforme Big Data sur Microsoft Azure pour centraliser ses flux data, stocker des pétaoctets de données dans des Data Lakes et industrialiser des cas d?usage IA stratégiques. La Data Science joue un rôle clé, notamment dans les projets de maintenance prédictive, d?information voyageurs et d?optimisation opérationnelle.
Missions principalesDévelopper des modèles de Machine Learning et d?IA sur des volumes massifs de données stockées sur Azure (Data Lake, Data Factory, Databricks).
Construire des features temporelles, utiliser des séries temporelles ou des méthodes statistiques avancées pour modéliser des phénomènes (ex : retards, maintenance).
Analyser les données météorologiques, de trafic, IoT, capteurs ou autres sources pour créer des prédictions (ex : retards, pannes) ou des systèmes d?alerte.
Industrialiser les pipelines d?entrainement et d?inférence sur Azure (notamment via Azure Databricks, Azure ML, etc.).
Monitorer les performances des modèles, mettre en place des métriques qualité, des alertes, des feedback loops.
Collaborer avec les équipes infrastructure / Data Engineering pour garantir la scalabilité et la gouvernance des flux data.
Accompagner les équipes métier (opération, maintenance, transport, marketing) dans l?exploitation des modèles prédictifs.
Documenter les modèles, écrire des rapports, créer des visualisations et restituer les résultats de manière pédagogique.
Cloud Azure : Data Lake, Data Factory, Databricks.
Big Data : Spark (Scala ou Python) pour traitement distribué.
Langages : Python (pandas, scikit-learn, ML frameworks), SQL / T-SQL.
Machine Learning / IA : régression, classification, séries temporelles, modèles statistiques, ou algorithmes supervisés / non supervisés.
Data Engineering / Pipeline : connaissance des pipelines ETL/ELT, ingestion de données, feature engineering.
MLOps : pipelines de déploiement, scoring, orchestration, monitoring, versioning des modèles.
Gouvernance des données : qualité, sécurité, catalogage.
Architecture des données : conception de schémas, datalakes, modélisation.
Requirements
Compétences transversesEsprit analytique et méthodique.
Capacité à vulgariser des concepts complexes auprès des équipes métier.
Autonomie, rigueur, curiosité et force de proposition.
Aisance relationnelle et collaboration interdisciplinaire (Data, produit, exploitation).
Capacité à prioriser et structurer le travail sur des sujets long terme.
Profil recherchéFormation : Bac+5 (informatique, data, maths, statistique, IA?).
Expérience : minimum 3 à 6 ans en data science / machine learning, idéalement sur des environnements cloud / Big Data.
Langues : bon niveau d?anglais technique.
Atout : expérience antérieure dans le transport, l?IoT, la maintenance, ou de lourdes infrastructures data., Profil recherchéFormation : Bac+5 (informatique, data, maths, statistique, IA?).
Expérience : minimum 3 à 6 ans en data science / machine learning, idéalement sur des environnements cloud / Big Data.
Langues : bon niveau d?anglais technique.
Atout : expérience antérieure dans le transport, l?IoT, la maintenance, ou de lourdes infrastructures data.