Développeur Java Big Data Senior - Spark/Kafka F/H
Invivoo
Canton de Montigny-le-Bretonneux, France
8 days ago
Role details
Contract type
Permanent contract Employment type
Full-time (> 32 hours) Working hours
Regular working hours Languages
French, English Experience level
SeniorJob location
Canton de Montigny-le-Bretonneux, France
Tech stack
Java
Amazon Web Services (AWS)
Big Data
Databases
Continuous Integration
DevOps
PostgreSQL
MongoDB
NoSQL
Platform as a Service (PAAS)
Performance Tuning
Spark
Reliability of Systems
Backend
Kubernetes
Kafka
GraphQL
Docker
Microservices
Job description
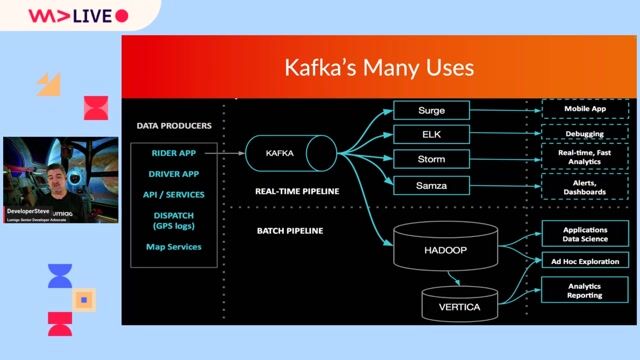
L'objectif principal est de concevoir et d'optimiser une solution de diffusion des événements de trading, qui collecte, normalise et transmet des données issues de divers systèmes de booking. La montée en charge est prévue avec l'intégration prochaine de nouvelles catégories d'événements, pour atteindre une volumétrie allant jusqu'à 2-3 millions de trades par jour.
Environnement technique :
- Conception et développement de microservices en Java 21
- Mise en place et optimisation du streaming de données avec Apache Kafka
- Déploiement et gestion des conteneurs via Docker, Kubernetes et Helm
- Participation à l'intégration de MongoDB et à l'évolution vers GraphQL
- Optimisation des performances pour répondre aux enjeux de haute volumétrie et de temps réel
- Industrialisation et automatisation des déploiements avec CI/CD et DevOps
- Monitoring et suivi de la production pour garantir la disponibilité et la fiabilité du système
Nous recherchons un développeur back-end confirmé avec une expertise en Java / Kafka / Microservices et une solide connaissance des architectures distribuées et des contraintes de haute volumétrie.
Requirements
- Expérience en développement Java 21
- Maîtrise d'Apache Kafka pour le streaming de données
- Expérience avec Docker, Kubernetes et Helm
- Bonne connaissance des bases de données SQL et NoSQL (PostgreSQL, MongoDB, ELK)
- Maîtrise des pratiques CI/CD et DevOps
- Expérience en environnement cloud (AWS PaaS est un plus)
- Bon niveau d'anglais requis
About the company
Au sein d'une Banque d'Investissement, une équipe stratégique dédiée à la gestion et à la distribution de données en temps réel recherche un Développeur Java Senior pour renforcer ses projets innovants., Créée en 2004, INVIVOO est une ESN, partenaire technologique et historique des institutions financières depuis plus de 20 ans. Nous mobilisons nos expertises technologiques et métiers au service de nos clients pour les accompagner dans le secteur de la banque, finance et de l'assurance. Nous sommes plus de 200 collaborateurs, ambassadeurs de nos valeurs : proximité, engagement, questionnement, plaisir.