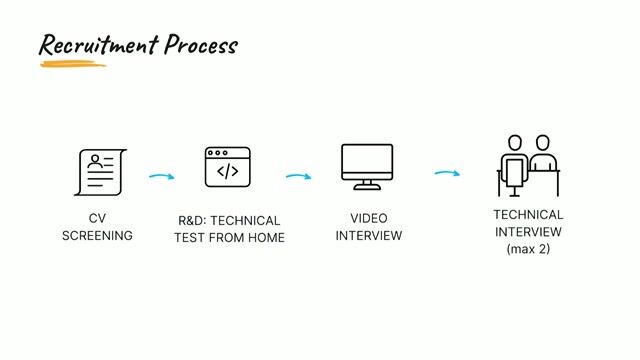
Data Engineer
Role details
Job location
Tech stack
Job description
We are seeking a motivated Data Engineer to streamline our data management and development to build complex and data-driven experiences. You will play a crucial role in our project teams, ensuring an efficient collection, flow and transformation of data, ultimately contributing to the creation of impactful data visualizations and product strategy., As a Data Engineer, you'll collaborate with designers, developers, and data specialists to turn data into actionable insights and reliable product features. Ensuring quality, reproducibility, accuracy, and security in our data pipelines will be a key part of your role.
Our data approach and tech stack are flexible, tailored to each project's needs. Data may come as files, in cloud storage, databases, or via APIs. You'll work to understand a project's data requirements and translate them into reliable pipelines, maintainable databases, and, where relevant, integrate external open data sources., We find it important that you grow and challenge yourself and we want to ensure that you are supported in this. That's why we offer:
- Training courses: tailored to your experience level and needs, personal development planning, and feedback sessions.
- Our People & Culture Manager and your Lead will help you with your professional and personal development.
- CLEVER°FRANKE Development week: about 3 times a year, we organize a week where the entire studio fully focuses on personal and professional growth, outside of client projects.
- CLEVER°FRANKE Prototype Day: a day full of creativity, innovation, learning, and working with colleagues in a hands-on environment.
Requirements
You have at least 2 years of experience in data engineering and a keen interest in data visualization and product development. You're methodical, detail-oriented, and take initiative in your domain. Key skills include:
- Building and maintaining data infrastructure, including ETL pipelines, orchestration, and validation
- Proficiency in Python, SQL, and database management
- Data modeling, API design, and cloud infrastructure experience
- Version control with Git and collaborative software development
- Familiarity with modern data engineering tools and frameworks for pipeline orchestration, validation, and testing (e.g., Dagster, Pandera, Airflow, Great Expectations)
- Monitoring, debugging, and ensuring reliability of data pipelines
- Proactive in suggesting and implementing project-specific solutions
We'd be especially excited if you also have experience in:
- Data science
- Data visualization and prototyping
- Experience with Graph databases like Neo4j, Neptune or CosmosDB
- Developing AI-driven products, including integration with LLMs through APIs (e.g. OpenAI, Anthropic) or self-hosted models
Benefits & conditions
- A competitive salary, based on your background and experience;
- Support from a friendly, passionate, down-to-earth team;
- A personal development budget of 1000 euro per year for trainings tailored to your personal and professional growth;
- A personal wellbeing budget of 250 euros per year (purchase a bike, fitness or yoga membership);
- Two extra holidays per calendar year, because we all have events in our life that we need time for (weddings, celebrating religious or cultural events);
- Hybrid working from our studio or home - (at least 2 days per week in the studio);
- A healthy, abundant lunch every day in the studio;
- Paid train expenses from your home to the studio;
- A collective pension plan;
- A MacBook and all the peripherals you need;
- Inspiring team events; such as our annual team prototyping day, team trainings, sport events and conference visits.