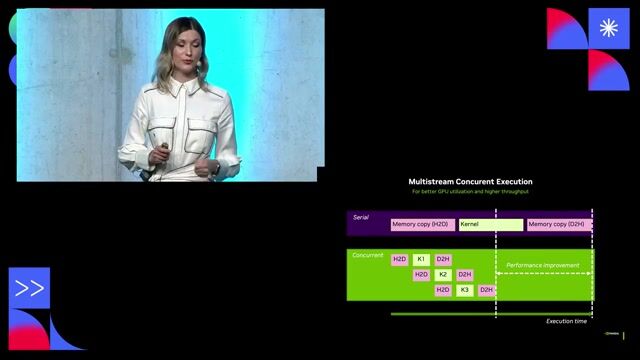
Senior Site Reliability Engineer - AI/ML optimized GPU clusters
The Next Chapter
10 days ago
Role details
Contract type
Permanent contract Employment type
Full-time (> 32 hours) Working hours
Regular working hours Languages
English Experience level
SeniorJob location
Tech stack
Artificial Intelligence
Unix
C++
Cloud Computing
Configuration Management
Continuous Integration
Data Structures
Distributed Systems
Fault Tolerance
Python
Reliability Engineering
Ansible
Graphics Processing Unit (GPU)
Backend
Containerization
Terraform
Docker
Programming Languages
Job description
Your responsibilities will include:
- Ensure fault-tolerance, scale, and uninterrupted operations for the service.
- Use cutting-edge cloud technology to solve a variety of infrastructure problems.
- Implement and improve CI/CD processes.
Requirements
Do you have experience in UNIX?, * Solid experience with programming languages (like Go, Python, or C++), beyond scripting;
- You have experience in environments with a multitude of GPUs distributed over multiple nodes;
- Good understanding of classic algorithms and data structures;
- Commercial experience with, and deep understanding of, Unix/Linux systems and network technology;
- Solid experience with CI/CD and IaC;
- Experience with containerization and configuration management (Ansible, Salt, Terraform, Docker, Kubenetes, Helm).
It will be an added bonus if you have:
- A desire to be involved in backend development;
- Experience designing, developing, and running high-load distributed systems;
- Experience with a variety of cloud platforms.
Coding interviews are part of the process.
Benefits & conditions
- Competitive salary and comprehensive benefits package.
- Opportunities for professional growth and taking ownership in a massivley scaling environment.
- Flexible working arrangements.
- A dynamic and collaborative work environment that values initiative and innovation.
- On-site in Amsterdam or full-remote (across Europe).