Senior Azure Data Engineer (ID: 3508)
Stafide
Eindhoven, Netherlands
7 days ago
Role details
Contract type
Permanent contract Employment type
Full-time (> 32 hours) Working hours
Regular working hours Languages
English Experience level
SeniorJob location
Eindhoven, Netherlands
Tech stack
Sql Data Warehouse
Azure
Information Engineering
Data Governance
Data Systems
DevOps
High-Level Architecture
Python
SQL Azure
NoSQL
Azure
SQL Databases
Technical Data Management Systems
Data Processing
Data Ingestion
Azure
Spark
PySpark
Cosmos DB
Stream Analytics
Data Pipelines
Serverless Computing
Databricks
Job description
- Design and implement scalable data solutions based on high-level architecture.
- Build and optimize end-to-end data pipelines using Azure Databricks.
- Load and process data from disparate data sources into centralized platforms.
- Perform preprocessing, transformation, and enrichment using PySpark and Spark-SQL.
- Work directly with stakeholders to gather business requirements for data pipeline and lake migration initiatives.
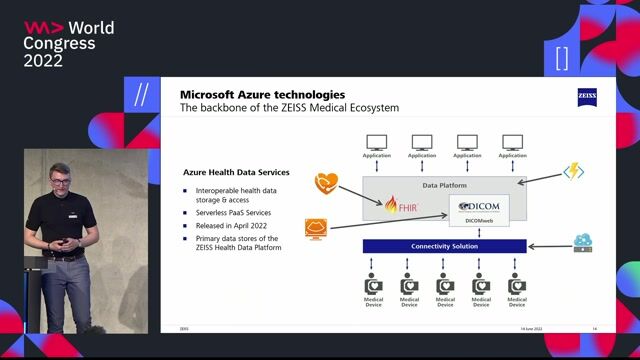
- Develop and maintain data solutions using Azure services such as ADLS, ADF, Cosmos DB, and Azure SQL DW.
- Implement serverless architectures using Azure Functions.
- Monitor and manage Azure DevOps and Databricks pipelines.
- Participate in production support and incident resolution.
- Contribute to data governance practices using Unity Catalog.
- Support ARM template-based infrastructure deployments.
- Continuously improve pipeline performance, reliability, and scalability.
Requirements
- 8-10 years of hands-on experience in data engineering and Azure ecosystem.
- Strong expertise in Python and Scala for data processing.
- Deep knowledge of SQL and NoSQL databases.
- Advanced experience with PySpark and Spark-SQL.
- Strong hands-on experience with Azure Databricks.
- Practical experience with Azure Data Lake Storage (ADLS) and Azure Data Factory (ADF).
- Experience working with Stream Analytics, SQL Data Warehouse, and Cosmos DB.
- Solid exposure to Azure DevOps practices.
You should possess the ability to:
- Design independent solutions from high-level architecture without constant supervision.
- Translate business requirements into technical data solutions.
- Handle complex data ingestion from multiple heterogeneous sources.
- Optimize Spark workloads for performance and cost efficiency.
- Monitor and troubleshoot production pipelines effectively.
- Collaborate cross-functionally with business and technical stakeholders.
- Implement data governance and access control using Unity Catalog.
- Automate deployments using DevOps and Infrastructure-as-Code practices.