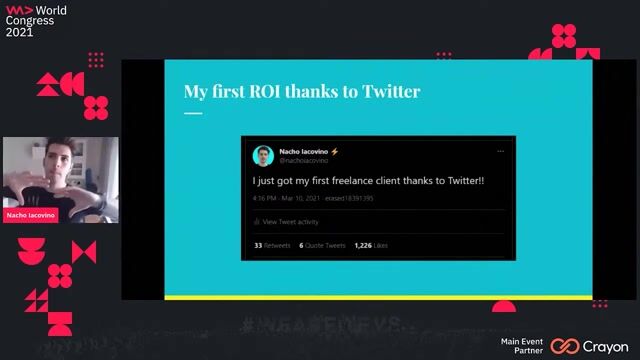
Twitter Developer Portal
Role details
Job location
Tech stack
Job description
You signed in with another tab or window. Reload to refresh your session. You signed out in another tab or window. Reload to refresh your session. You switched accounts on another tab or window. Reload to refresh your session. Dismiss alert {{ message }} yichuan-w / LEANN Public
- Notifications You must be signed in to change notification settings
- Fork 865
- Star 10k [MLsys2026]: RAG on Everything with LEANN. Enjoy 97% storage savings while running a fast, accurate, and 100% private RAG application on your personal device. arxiv.org/abs/2506.08276
License MIT license 10k stars 865 forks Branches Tags Activity Star Notifications You must be signed in to change notification settings
-
Code
-
Issues 38
-
Pull requests 13
-
Discussions
-
Actions
-
Projects 0
-
Security 0
-
Insights Additional navigation options
-
Code
-
Issues
-
Pull requests
-
Discussions
-
Actions
-
Projects
-
Security
-
Insights, Clone the repository to access all examples and try amazing applications, git clone https://github.com/yichuan-w/LEANN.git leann cd leann and install LEANN from PyPI to run them immediately: uv venv source .venv/bin/activate uv pip install leann
CPU-only (Linux): use the cpu extra (e.g. leann[cpu])
Build from Source (Recommended for development)
git clone https://github.com/yichuan-w/LEANN.git leann
cd leann
git submodule update --init --recursive
macOS:
Note: DiskANN requires MacOS 13.3 or later.
brew install libomp boost protobuf zeromq pkgconf
uv sync --extra diskann
Linux (Ubuntu/Debian):
Note: On Ubuntu 20.04, you may need to build a newer Abseil and pin Protobuf (e.g., v3.20.x) for building DiskANN. See Issue #30 for a step-by-step note.
You can manually install Intel oneAPI MKL instead of libmkl-full-dev for DiskANN. You can also use libopenblas-dev for building HNSW only, by removing --extra diskann in the command below.
sudo apt-get update && sudo apt-get install -y
libomp-dev libboost-all-dev protobuf-compiler libzmq3-dev
pkg-config libabsl-dev libaio-dev libprotobuf-dev
libmkl-full-dev
uv sync --extra diskann
Linux (Arch Linux):
sudo pacman -Syu && sudo pacman -S --needed base-devel cmake pkgconf git gcc
boost boost-libs protobuf abseil-cpp libaio zeromq
For MKL in DiskANN
sudo pacman -S --needed base-devel git git clone https://aur.archlinux.org/paru-bin.git cd paru-bin && makepkg -si paru -S intel-oneapi-mkl intel-oneapi-compiler source /opt/intel/oneapi/setvars.sh
uv sync --extra diskann
Linux (RHEL / CentOS Stream / Oracle / Rocky / AlmaLinux):
See Issue #50 for more details.
sudo dnf groupinstall -y "Development Tools"
sudo dnf install -y libomp-devel boost-devel protobuf-compiler protobuf-devel
abseil-cpp-devel libaio-devel zeromq-devel pkgconf-pkg-config
For MKL in DiskANN
sudo dnf install -y intel-oneapi-mkl intel-oneapi-mkl-devel
intel-oneapi-openmp || sudo dnf install -y intel-oneapi-compiler
source /opt/intel/oneapi/setvars.sh
uv sync --extra diskann
Quick Start
Our declarative API makes RAG as easy as writing a config file.
Check out demo.ipynb or
from leann import LeannBuilder, LeannSearcher, LeannChat
from pathlib import Path
INDEX_PATH = str(Path("./").resolve() / "demo.leann"), LEANN supports many LLM providers for text generation (HuggingFace, Ollama, Anthropic, and Any OpenAI compatible API).
OpenAI API Setup (Default)
Set your OpenAI API key as an environment variable:
export OPENAI_API_KEY="your-api-key-here"
Make sure to use --llm openai flag when using the CLI. You can also specify the model name with --llm-model
--embedding-mode openai
--embedding-model jina-embeddings-v3
--embedding-api-base https://api.jina.ai/v1
--embedding-api-key $JINA_API_KEY
If your provider isn't on this list, don't worry! Check their documentation for an OpenAI-compatible endpoint-chances are, it's OpenAI Compatible too! Ollama Setup (Recommended for full privacy) macOS: First, download Ollama for macOS.
Pull a lightweight model (recommended for consumer hardware)
ollama pull llama3.2:1b Linux:
Install Ollama
curl -fsSL https://ollama.ai/install.sh | sh
Start Ollama service manually
ollama serve &
Pull a lightweight model (recommended for consumer hardware)
ollama pull llama3.2:1b
Flexible Configuration LEANN provides flexible parameters for embedding models, search strategies, and data processing to fit your specific needs. Need configuration best practices? Check our Configuration Guide for detailed optimization tips, model selection advice, and solutions to common issues like slow embeddings or poor search quality., Ask questions directly about your personal PDFs, documents, and any directory containing your files! The example below asks a question about summarizing our paper (uses default data in data/, which is a directory with diverse data sources: two papers, Pride and Prejudice, and a Technical report about LLM in Huawei in Chinese), and this is the easiest example to run here: source .venv/bin/activate # Don't forget to activate the virtual environment python -m apps.document_rag --query "What are the main techniques LEANN explores?" Click to expand: Document-Specific Arguments
Parameters --data-dir DIR # Directory containing documents to process (default: data) --file-types .ext .ext # Filter by specific file types (optional - all LlamaIndex supported types if omitted)
Example Commands
Process all documents with larger chunks for academic papers
python -m apps.document_rag --data-dir "~/Documents/Papers" --chunk-size 1024
Filter only markdown and Python files with smaller chunks
python -m apps.document_rag --data-dir "./docs" --chunk-size 256 --file-types .md .py
Enable AST-aware chunking for code files
python -m apps.document_rag --enable-code-chunking --data-dir "./my_project"
Or use the specialized code RAG for better code understanding
python -m apps.code_rag --repo-dir "./my_codebase" --query "How does authentication work?"
ColQwen: Multimodal PDF Retrieval with Vision-Language Models Search through PDFs using both text and visual understanding with ColQwen2/ColPali models. Perfect for research papers, technical documents, and any PDFs with complex layouts, figures, or diagrams.
Mac Users: ColQwen is optimized for Apple Silicon with MPS acceleration for faster inference!
Build index from PDFs
python -m apps.colqwen_rag build --pdfs ./my_papers/ --index research_papers
Search with text queries
python -m apps.colqwen_rag search research_papers "How does attention mechanism work?"
Interactive Q&A
python -m apps.colqwen_rag ask research_papers --interactive Click to expand: ColQwen Setup & Usage
Prerequisites
Install dependencies
uv pip install colpali_engine pdf2image pillow matplotlib qwen_vl_utils einops seaborn brew install poppler # macOS only, for PDF processing
Build Index
python -m apps.colqwen_rag build
--pdfs ./pdf_directory/
--index my_index
--model colqwen2 # or colpali
Search python -m apps.colqwen_rag search my_index "your question here" --top-k 5
Models
-
ColQwen2 (colqwen2): Latest vision-language model with improved performance
-
ColPali (colpali): Proven multimodal retriever For detailed usage, see the ColQwen Guide., First, you need to install the WeChat exporter, brew install sunnyyoung/repo/wechattweak-cli or install it manually (if you have issues with Homebrew): sudo packages/wechat-exporter/wechattweak-cli install Troubleshooting:
-
Installation issues: Check the WeChatTweak-CLI issues page
-
Export errors: If you encounter the error below, try restarting WeChat Failed to export WeChat data. Please ensure WeChat is running and WeChatTweak is installed. Failed to find or export WeChat data. Exiting. Click to expand: WeChat-Specific Arguments
Parameters --export-dir DIR # Directory to store exported WeChat data (default: wechat_export_direct) --force-export # Force re-export even if data exists
Example Commands
Search for travel plans discussed in group chats
python -m apps.wechat_rag --query "travel plans" --max-items 10000
Re-export and search recent chats (useful after new messages)
python -m apps.wechat_rag --force-export --query "work schedule" Click to expand: Example queries you can try Once the index is built, you can ask questions like:
- "我想买魔术师约翰逊的球衣,给我一些对应聊天记录?" (Chinese: Show me chat records about buying Magic Johnson's jersey)
ChatGPT Chat History: Your Personal AI Conversation Archive! Transform your ChatGPT conversations into a searchable knowledge base! Search through all your ChatGPT discussions about coding, research, brainstorming, and more. python -m apps.chatgpt_rag --export-path chatgpt_export.html --query "How do I create a list in Python?" Unlock your AI conversation history. Never lose track of valuable insights from your ChatGPT discussions again., + .html files from ChatGPT exports
- .zip archives from ChatGPT
- Directories with multiple export files Click to expand: ChatGPT-Specific Arguments
Parameters --export-path PATH # Path to ChatGPT export file (.html/.zip) or directory (default: ./chatgpt_export) --separate-messages # Process each message separately instead of concatenated conversations --chunk-size N # Text chunk size (default: 512) --chunk-overlap N # Overlap between chunks (default: 128)
Example Commands
Basic usage with HTML export
python -m apps.chatgpt_rag --export-path conversations.html
Process ZIP archive from ChatGPT
python -m apps.chatgpt_rag --export-path chatgpt_export.zip
Search with specific query
python -m apps.chatgpt_rag --export-path chatgpt_data.html --query "Python programming help"
Process individual messages for fine-grained search
python -m apps.chatgpt_rag --separate-messages --export-path chatgpt_export.html
Process directory containing multiple exports
python -m apps.chatgpt_rag --export-path ./chatgpt_exports/ --max-items 1000 Click to expand: Example queries you can try Once your ChatGPT conversations are indexed, you can search with queries like:
- "What did I ask ChatGPT about Python programming?"
- "Show me conversations about machine learning algorithms"
- "Find discussions about web development frameworks"
- "What coding advice did ChatGPT give me?"
- "Search for conversations about debugging techniques"
- "Find ChatGPT's recommendations for learning resources"
Claude Chat History: Your Personal AI Conversation Archive! Transform your Claude conversations into a searchable knowledge base! Search through all your Claude discussions about coding, research, brainstorming, and more. python -m apps.claude_rag --export-path claude_export.json --query "What did I ask about Python dictionaries?" Unlock your AI conversation history. Never lose track of valuable insights from your Claude discussions again., Note: Claude export methods may vary depending on the interface you're using. Check Claude's help documentation for the most current export instructions. Supported formats:
- .json files (recommended)
- .zip archives containing JSON data
- Directories with multiple export files Click to expand: Claude-Specific Arguments
Parameters --export-path PATH # Path to Claude export file (.json/.zip) or directory (default: ./claude_export) --separate-messages # Process each message separately instead of concatenated conversations --chunk-size N # Text chunk size (default: 512) --chunk-overlap N # Overlap between chunks (default: 128)
Example Commands
Basic usage with JSON export
python -m apps.claude_rag --export-path my_claude_conversations.json
Process ZIP archive from Claude
python -m apps.claude_rag --export-path claude_export.zip
Search with specific query
python -m apps.claude_rag --export-path claude_data.json --query "machine learning advice"
Process individual messages for fine-grained search
python -m apps.claude_rag --separate-messages --export-path claude_export.json
Process directory containing multiple exports
python -m apps.claude_rag --export-path ./claude_exports/ --max-items 1000 Click to expand: Example queries you can try Once your Claude conversations are indexed, you can search with queries like:
- "What did I ask Claude about Python programming?"
- "Show me conversations about machine learning algorithms"
- "Find discussions about software architecture patterns"
- "What debugging advice did Claude give me?"
- "Search for conversations about data structures"
- "Find Claude's recommendations for learning resources"
iMessage History: Your Personal Conversation Archive! Transform your iMessage conversations into a searchable knowledge base! Search through all your text messages, group chats, and conversations with friends, family, and colleagues. python -m apps.imessage_rag --query "What did we discuss about the weekend plans?" Unlock your message history. Never lose track of important conversations, shared links, or memorable moments from your iMessage history. Click to expand: How to Access iMessage Data iMessage data location: iMessage conversations are stored in a SQLite database on your Mac at: ~/Library/Messages/chat.db
Important setup requirements:
-
Grant Full Disk Access to your terminal or IDE: o Open System Preferences * Security & Privacy * Privacy o Select Full Disk Access from the left sidebar o Click the + button and add your terminal app (Terminal, iTerm2) or IDE (VS Code, etc.) o Restart your terminal/IDE after granting access
-
Alternative: Use a backup database o If you have Time Machine backups or manual copies of the database o Use --db-path to specify a custom location Supported formats:
- Direct access to ~/Library/Messages/chat.db (default)
- Custom database path with --db-path
- Works with backup copies of the database Click to expand: iMessage-Specific Arguments
Parameters --db-path PATH # Path to chat.db file (default: ~/Library/Messages/chat.db) --concatenate-conversations # Group messages by conversation (default: True) --no-concatenate-conversations # Process each message individually --chunk-size N # Text chunk size (default: 1000) --chunk-overlap N # Overlap between chunks (default: 200)
Example Commands
Basic usage (requires Full Disk Access)
python -m apps.imessage_rag
Search with specific query
python -m apps.imessage_rag --query "family dinner plans"
Use custom database path
python -m apps.imessage_rag --db-path /path/to/backup/chat.db
Process individual messages instead of conversations
python -m apps.imessage_rag --no-concatenate-conversations
Limit processing for testing
python -m apps.imessage_rag --max-items 100 --query "weekend" Click to expand: Example queries you can try Once your iMessage conversations are indexed, you can search with queries like:
-
"What did we discuss about vacation plans?"
-
"Find messages about restaurant recommendations"
-
"Show me conversations with John about the project"
-
"Search for shared links about technology"
-
"Find group chat discussions about weekend events"
-
"What did mom say about the family gathering?", Connect to live data sources through the Model Context Protocol (MCP). LEANN now supports real-time RAG on platforms like Slack, Twitter, and more through standardized MCP servers. Key Benefits:
-
Live Data Access: Fetch real-time data without manual exports
-
Standardized Protocol: Use any MCP-compatible server
-
Easy Extension: Add new platforms with minimal code
-
Secure Access: MCP servers handle authentication
Slack Messages: Search Your Team Conversations Transform your Slack workspace into a searchable knowledge base! Find discussions, decisions, and shared knowledge across all your channels.
Test MCP server connection
python -m apps.slack_rag --mcp-server "slack-mcp-server" --test-connection
Index and search Slack messages
python -m apps.slack_rag
--mcp-server "slack-mcp-server"
--workspace-name "my-team"
--channels general dev-team random
--query "What did we decide about the product launch?"
Comprehensive Setup Guide: For detailed setup instructions, troubleshooting common issues (like "users cache is not ready yet"), and advanced configuration options, see our Slack Setup Guide.
Quick Setup:
-
Install a Slack MCP server (e.g., npm install -g slack-mcp-server)
-
Create a Slack App and get API credentials (see detailed guide above)
-
Set environment variables: export SLACK_BOT_TOKEN="xoxb-your-bot-token" export SLACK_APP_TOKEN="xapp-your-app-token" # Optional
-
Test connection with --test-connection flag Arguments:
- --mcp-server: Command to start the Slack MCP server
- --workspace-name: Slack workspace name for organization
- --channels: Specific channels to index (optional)
- --concatenate-conversations: Group messages by channel (default: true)
- --max-messages-per-channel: Limit messages per channel (default: 100)
- --max-retries: Maximum retries for cache sync issues (default: 5)
- --retry-delay: Initial delay between retries in seconds (default: 2.0)
Twitter Bookmarks: Your Personal Tweet Library Search through your Twitter bookmarks! Find that perfect article, thread, or insight you saved for later.
Test MCP server connection
python -m apps.twitter_rag --mcp-server "twitter-mcp-server" --test-connection
Index and search Twitter bookmarks
python -m apps.twitter_rag
--mcp-server "twitter-mcp-server"
--max-bookmarks 1000
--query "What AI articles did I bookmark about machine learning?"
Setup Requirements:
-
Install a Twitter MCP server (e.g., npm install -g twitter-mcp-server)
-
Get Twitter API credentials: o Apply for a Twitter Developer Account at developer.twitter.com o Create a new app in the Twitter Developer Portal o Generate API keys and access tokens with "Read" permissions o For bookmarks access, you may need Twitter API v2 with appropriate scopes export TWITTER_API_KEY="your-api-key" export TWITTER_API_SECRET="your-api-secret" export TWITTER_ACCESS_TOKEN="your-access-token" export TWITTER_ACCESS_TOKEN_SECRET="your-access-token-secret"
-
Test connection with --test-connection flag Arguments:
-
--mcp-server: Command to start the Twitter MCP server
-
--username: Filter bookmarks by username (optional)
-
--max-bookmarks: Maximum bookmarks to fetch (default: 1000)
-
--no-tweet-content: Exclude tweet content, only metadata
-
--no-metadata: Exclude engagement metadata Click to expand: Example queries you can try Slack Queries:
-
"What did the team discuss about the project deadline?"
-
"Find messages about the new feature launch"
-
"Show me conversations about budget planning"
-
"What decisions were made in the dev-team channel?" Twitter Queries:
-
"What AI articles did I bookmark last month?"
-
"Find tweets about machine learning techniques"
-
"Show me bookmarked threads about startup advice"
-
"What Python tutorials did I save?" Using MCP with CLI Commands Want to use MCP data with regular LEANN CLI? You can combine MCP apps with CLI commands:
Step 1: Use MCP app to fetch and index data
python -m apps.slack_rag --mcp-server "slack-mcp-server" --workspace-name "my-team"
Step 2: The data is now indexed and available via CLI
leann search slack_messages "project deadline" leann ask slack_messages "What decisions were made about the product launch?"
Same for Twitter bookmarks
python -m apps.twitter_rag --mcp-server "twitter-mcp-server" leann search twitter_bookmarks "machine learning articles" MCP vs Manual Export:
- MCP: Live data, automatic updates, requires server setup
- Manual Export: One-time setup, works offline, requires manual data export Adding New MCP Platforms Want to add support for other platforms? LEANN's MCP integration is designed for easy extension:
- Find or create an MCP server for your platform
- Create a reader class following the pattern in apps/slack_data/slack_mcp_reader.py
- Create a RAG application following the pattern in apps/slack_rag.py
- Test and contribute back to the community! Popular MCP servers to explore:
- GitHub repositories and issues
- Discord messages
- Notion pages
- Google Drive documents
- And many more in the MCP ecosystem!, # build from a specific directory, and my_docs is the index name(Here you can also build from multiple dict or multiple files) leann build my-docs --docs ./your_documents
Search your documents
leann search my-docs "machine learning concepts"
Interactive chat with your documents
leann ask my-docs --interactive
Ask a single question (non-interactive)
leann ask my-docs "Where are prompts configured?"
Detect file changes since last build/watch checkpoint
leann watch my-docs
List all your indexes
leann list
Remove an index
leann remove my-docs Key CLI features:
- Auto-detects document formats (PDF, TXT, MD, DOCX, PPTX + code files)
- AST-aware chunking for Python, Java, C#, TypeScript files
- Smart text chunking with overlap for all other content
- File change detection via Merkle tree snapshots (leann watch)
- Multiple LLM providers (Ollama, OpenAI, HuggingFace)
- Organized index storage in .leann/indexes/ (project-local)
- Support for advanced search parameters Click to expand: Complete CLI Reference You can use leann --help, or leann build --help, leann search --help, leann watch --help, leann ask --help, leann list --help, leann remove --help to get the complete CLI reference. Build Command: leann build INDEX_NAME --docs DIRECTORY|FILE [DIRECTORY|FILE ...] [OPTIONS]
Options:
--backend {hnsw,diskann} Backend to use (default: hnsw)
--embedding-model MODEL Embedding model (default: facebook/contriever)
--graph-degree N Graph degree (default: 32)
--complexity N Build complexity (default: 64)
--force Force rebuild existing index
--compact / --no-compact Use compact storage (default: true). Must be no-compact for no-recompute build.
--recompute / --no-recompute Enable recomputation (default: true)
Search Command:
leann search INDEX_NAME QUERY [OPTIONS], recompute / --no-recompute Enable/disable embedding recomputation (default: enabled). Should not do a no-recompute search in a recompute build.
--pruning-strategy {global,local,proportional}
Watch Command:
leann watch INDEX_NAME
Compares the current file system state against the last checkpoint (Merkle tree snapshot)
and reports which files have been added, removed, or modified, along with their chunk IDs.
- Automatically saves a new checkpoint after detecting changes
- Each subsequent run compares against the most recent checkpoint
- File change detection uses SHA-256 content hashing via a Merkle tree
Example output:
=== Changes since last checkpoint ===
modified (1):
- /path/to/file.py
chunks: 42, 43, 44
Ask Command: leann ask INDEX_NAME [OPTIONS]
Options: --llm {ollama,openai,hf,anthropic} LLM provider (default: ollama) --model MODEL Model name (default: qwen3:8b) --interactive Interactive chat mode --top-k N Retrieval count (default: 20) List Command: leann list
Lists all indexes across all projects with status indicators:
- Index is complete and ready to use
- Index is incomplete or corrupted
- CLI-created index (in .leann/indexes/)
- App-created index (*.leann.meta.json files)
Remove Command: leann remove INDEX_NAME [OPTIONS]
Options: --force, -f Force removal without confirmation
Smart removal: automatically finds and safely removes indexes
- Shows all matching indexes across projects
- Requires confirmation for cross-project removal
- Interactive selection when multiple matches found
- Supports both CLI and app-created indexes, The magic: Most vector DBs store every single embedding (expensive). LEANN stores a pruned graph structure (cheap) and recomputes embeddings only when needed (fast).
Core techniques:
-
Graph-based selective recomputation: Only compute embeddings for nodes in the search path
-
High-degree preserving pruning: Keep important "hub" nodes while removing redundant connections
-
Dynamic batching: Efficiently batch embedding computations for GPU utilization
-
Two-level search: Smart graph traversal that prioritizes promising nodes Backends:
-
HNSW (default): Ideal for most datasets with maximum storage savings through full recomputation
-
DiskANN: Advanced option with superior search performance, using PQ-based graph traversal with real-time reranking for the best speed-accuracy trade-off, author={Yichuan Wang and Shu Liu and Zhifei Li and Yongji Wu and Ziming Mao and Yilong Zhao and Xiao Yan and Zhiying Xu and Yang Zhou and Ion Stoica and Sewon Min and Matei Zaharia and Joseph E. Gonzalez}, year={2025}, eprint={2506.08276}, archivePrefix={arXiv}, primaryClass={cs.DB}, url={https://arxiv.org/abs/2506.08276}, }
Requirements
data
data
docker
docker
docs, README.md
demo.ipynb
demo.ipynb
llms.txt
llms.txt
pyproject.toml
Benefits & conditions
All RAG examples share these common parameters. Interactive mode is available in all examples - simply run without --query to start a continuous Q&A session where you can ask multiple questions. Type 'quit' to exit.
Environment Variables (GPU Device Selection)
LEANN_EMBEDDING_DEVICE # GPU for embedding model (e.g., cuda:0, cuda:1, cpu) LEANN_LLM_DEVICE # GPU for HFChat LLM (e.g., cuda:1, or "cuda" for multi-GPU auto)
Core Parameters (General preprocessing for all examples)
--index-dir DIR # Directory to store the index (default: current directory) --query "YOUR QUESTION" # Single query mode. Omit for interactive chat (type 'quit' to exit), and now you can play with your index interactively --max-items N # Limit data preprocessing (default: -1, process all data) --force-rebuild # Force rebuild index even if it exists
Embedding Parameters
--embedding-model MODEL # e.g., facebook/contriever, text-embedding-3-small, mlx-community/Qwen3-Embedding-0.6B-8bit or nomic-embed-text --embedding-mode MODE # sentence-transformers, openai, mlx, or ollama
LLM Parameters (Text generation models)
--llm TYPE # LLM backend: openai, ollama, hf, or anthropic (default: openai) --llm-model MODEL # Model name (default: gpt-4o) e.g., gpt-4o-mini, llama3.2:1b, Qwen/Qwen2.5-1.5B-Instruct --thinking-budget LEVEL # Thinking budget for reasoning models: low/medium/high (supported by o3, o3-mini, GPT-Oss:20b, and other reasoning models)
Search Parameters
--top-k N # Number of results to retrieve (default: 20) --search-complexity N # Search complexity for graph traversal (default: 32)
Chunking Parameters
--chunk-size N # Size of text chunks (default varies by source: 256 for most, 192 for WeChat) --chunk-overlap N # Overlap between chunks (default varies: 25-128 depending on source)
Index Building Parameters
--backend-name NAME # Backend to use: hnsw or diskann (default: hnsw)
--graph-degree N # Graph degree for index construction (default: 32)
--build-complexity N # Build complexity for index construction (default: 64)
--compact / --no-compact # Use compact storage (default: true). Must be no-compact for no-recompute build.
--recompute / --no-recompute # Enable/disable embedding recomputation (default: enabled). Should not do a no-recompute search in a recompute build., LEANN features intelligent code chunking that preserves semantic boundaries (functions, classes, methods) for Python, Java, C#, and TypeScript, improving code understanding compared to text-based chunking.
Read the AST Chunking Guide *
The future of code assistance is here. Transform your development workflow with LEANN's native MCP integration for Claude Code. Index your entire codebase and get intelligent code assistance directly in your IDE.
Key features:
- Semantic code search across your entire project, fully local index and lightweight
- AST-aware chunking preserves code structure (functions, classes)
- Context-aware assistance for debugging and development
- Zero-config setup with automatic language detection
Install LEANN globally for MCP integration
uv tool install leann-core --with leann claude mcp add --scope user leann-server -- leann_mcp
Setup is automatic - just start using Claude Code!
Try our fully agentic pipeline with auto query rewriting, semantic search planning, and more: Ready to supercharge your coding? Complete Setup Guide *