Data Scientist - JDC AI-Team
Jung, DMS & Cie. AG
Frankfurt am Main, Germany
2 days ago
Role details
Contract type
Permanent contract Employment type
Full-time (> 32 hours) Working hours
Regular working hours Languages
English, GermanJob location
Frankfurt am Main, Germany
Tech stack
Artificial Intelligence
Airflow
Data analysis
Databases
Continuous Integration
ETL
Python
Machine Learning
NoSQL
Azure
Software Engineering
Software Systems
SQL Databases
Unstructured Data
Management of Software Versions
Data Ingestion
Large Language Models
Prompt Engineering
Information Technology
Machine Learning Operations
Job description
- Du entwickelst, programmierst und betreibst Daten-, Machine-Learning- und AI-Pipelines (End-to-End: Datenaufnahme, Verarbeitung, Training, Deployment und Monitoring).
- Du entwickelst produktionsreife Softwarelösungen in Python und überführst Modelle zuverlässig in den operativen Betrieb.
- Du führst Explorative Datenanalysen (EDA) durch und identifizierst Muster, Trends und Anomalien in komplexen Datenbeständen.
- Du konzipierst, implementierst und optimierst Machine-Learning-Modelle zur Lösung konkreter geschäftlicher Fragestellungen.
- Du entwickelst und pflegst Prompt-Strategien (Prompt Engineering) für LLM-basierte Use Cases wie Extraktion, Klassifikation, Zusammenfassung und Q&A.
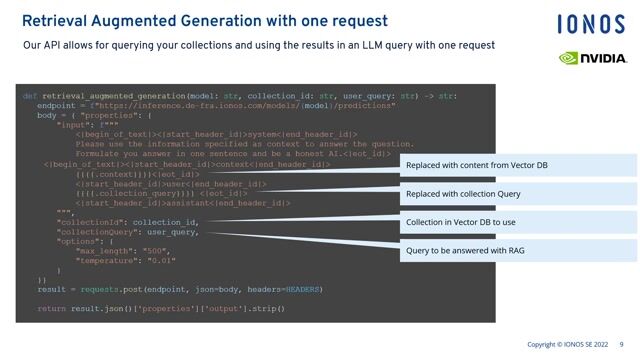
- Du arbeitest an LLM-Architekturen, z. B. Retrieval-Augmented Generation (RAG) und Vektor-Datenbanken.
- Du arbeitest eng mit Product, Engineering, BI und Fachbereichen zusammen, um skalierbare, automatisierte AI-Lösungen umzusetzen.
- Du stellst Qualität, Nachvollziehbarkeit, Wartbarkeit und Performance von Code, Modellen und Pipelines sicher.
- Du bereitest Analyse- und Modellergebnisse verständlich für technische und nicht-technische Stakeholder auf.
Requirements
- Ein abgeschlossenes Studium in Data Science, Informatik, Mathematik, Statistik oder einem vergleichbaren quantitativen Fachbereich.
- Mehrjährige praktische Erfahrung als Data Scientist, Machine-Learning-Engineer oder in einer vergleichbaren Rolle.
- Sehr gute Programmierkenntnisse in Python und Erfahrung mit produktionsnaher Softwareentwicklung.
- Fundierte Erfahrung mit Daten-, ML- oder AI-Pipelines (z. B. ETL/ELT, Feature-Pipelines, Training- und Inference-Workflows).
- Erfahrung mit MLOps- und Pipeline-Tools (z. B. Azure ML, MLflow, Airflow, CI/CD, Container-Workflows).
- Sehr gute Kenntnisse im Prompt Engineering für Large Language Models inkl. Testing, Versionierung und Optimierung von Prompts.
- Verständnis moderner LLM-Architekturen und Evaluierung von Modell- und Output-Qualität.
- Sicherer Umgang mit Datenbanken (SQL/NoSQL) sowie strukturierten und unstrukturierten Daten.
- Analytisches Denkvermögen, hohe Problemlösungskompetenz und ein ausgeprägter Engineering-Mindset.
- Sehr gute Deutsch- und Englischkenntnisse in Wort und Schrift (mindestens C1 Niveau entsprechend).
Benefits & conditions
- Mitarbeit in einem strategisch priorisierten, konzernweiten AI-Team mit direktem Einfluss auf daten- und KI-getriebene Entscheidungen.
- Anspruchsvolle AI- und Data-Science-Use-Cases mit echtem Produktiv- und Business-Impact - kein reines Research.
- Großen Gestaltungsspielraum bei Architektur, Pipelines, Modellen und Prompt-Strategien.
- Hybrides Arbeitsmodell mit modernen Arbeitsplätzen in Frankfurt am Main und flexiblen Remote-Optionen.
- Kurze Entscheidungswege und enge Zusammenarbeit mit Fachbereichen und Management.
- Individuelle Weiterbildungs- und Entwicklungsmöglichkeiten im Bereich Data Science, ML und GenAI.
- Attraktive Vergütung, moderne Arbeitsausstattung und ein kollegiales, leistungsorientiertes Umfeld.