Data Engineer - Kafka, Python and Hadoop
Role details
Job location
Tech stack
Job description
Job Title: Data Engineer - Kafka, Python and Hadoop Location: Sheffield, Birmingham, London- three days a week Salary/Rate: £520 daily rate Start Date: 20/04/2026 Job Type: Contract 7 months
Company Introduction: We have an exciting opportunity now available with one of our tier one banking clients! They are currently looking for a skilled Data Engineer, Kafka and Hadoop Expert(Python) to join their team for a seven-month contract.
Job Responsibilities/Objectives:
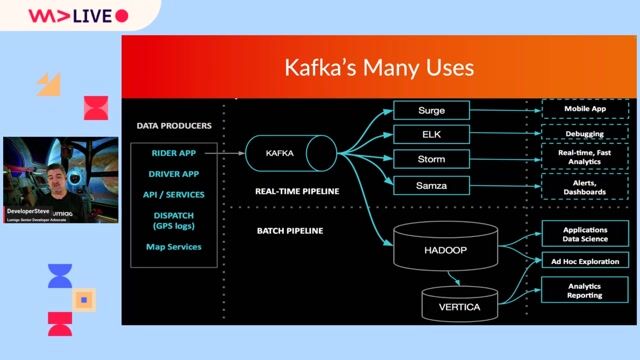
- Design and build Kafka-based streaming applications (Kafka Streams/ksqlDB) in Scala/Python for transformation, enrichment, and routing. . Implement end-to-end streaming pipelines: producers, stream processors, and consumers with strong data quality, idempotency, and DLQ patterns. . Model topics, schemas, and contracts (Avro/Protobuf/JSON) and maintain backward/forward compatibility. . Develop batch/stream interoperability: Spark/Structured Streaming jobs for aggregation, feature generation, and storage in Parquet/ORC.
Required Skills/Experience: The ideal candidate will have the following:
-
Kafka application development: Kafka Streams/ksqlDB, producer/consumer patterns, partitioning/serialization, exactly-once/at-least-once semantics. . Languages: Strong in Scala and/or Python for streaming apps; familiarity with testing frameworks and CI for stream processors. . Schema management: Avro/Protobuf/JSON, schema registry usage, compatibility strategies. . Stream/batch processing: Spark (including Structured Streaming), Parquet/ORC, partitioning/bucketing, performance tuning.
-
If you are interested in this opportunity, please apply now with your updated CV in Microsoft Word/PDF format.
-
Disclaimer
-
Notwithstanding any guidelines given to level of experience sought, we will consider candidates from outside this range if they can demonstrate the necessary competencies.
-
Square One is acting as both an employment agency and an employment business, and is an equal opportunities recruitment business. Square One embraces diversity and will treat everyone equally. Please see our website for our full diversity statement.
Requirements
-
Kafka application development: Kafka Streams/ksqlDB, producer/consumer patterns, partitioning/serialization, exactly-once/at-least-once semantics. . Languages: Strong in Scala and/or Python for streaming apps; familiarity with testing frameworks and CI for stream processors. . Schema management: Avro/Protobuf/JSON, schema registry usage, compatibility strategies. . Stream/batch processing: Spark (including Structured Streaming), Parquet/ORC, partitioning/bucketing, performance tuning.
-
If you are interested in this opportunity, please apply now with your updated CV in Microsoft Word/PDF format.
-
Disclaimer
-
Notwithstanding any guidelines given to level of experience sought, we will consider candidates from outside this range if they can demonstrate the necessary competencies.
-
Square One is acting as both an employment agency and an employment business, and is an equal opportunities recruitment business. Square One embraces diversity and will treat everyone equally. Please see our website for our full diversity statement.