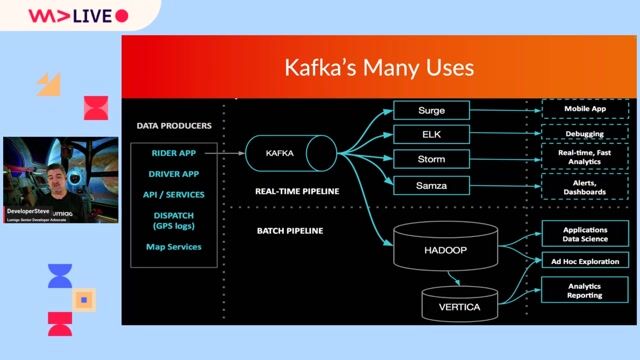
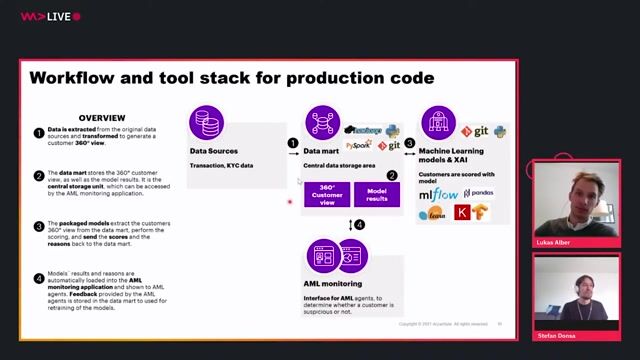
Hadoop PySpark, Python, Apache Kafka
Avance Consulting
Charlotte, United States of America
1 month ago
Role details
Contract type
Permanent contract Employment type
Full-time (> 32 hours) Working hours
Regular working hours Languages
English Experience level
IntermediateJob location
Charlotte, United States of America
Tech stack
HTML
Amazon Web Services (AWS)
Azure
Big Data
CSS
Cloud Computing
Code Review
Information Engineering
Data Governance
ETL
DevOps
Distributed Data Store
Hadoop
Hadoop Distributed File System
Hive
Python
Software Engineering
Data Streaming
TypeScript
Web Applications
Google Cloud Platform
Data Ingestion
Spark
Containerization
Angular
PySpark
Kubernetes
Information Technology
Kafka
Data Management
Front End Software Development
Api Design
REST
Docker
Microservices
Job description
- Define end-to-end architecture for data platforms, streaming systems, and web applications.
- Ensure alignment with enterprise standards, security, and compliance requirements.
- Evaluate emerging technologies and recommend adoption strategies.
Data Engineering :
- Design and implement data ingestion, transformation, and processing pipelines using Hadoop, PySpark, and related tools.
- Optimize ETL workflows for large-scale datasets and real-time streaming.
- Integrate Apache Kafka for event-driven architectures and messaging.
Application Development :
- Build and maintain backend services using Python and microservices architecture.
- Develop responsive, dynamic front-end applications using Angular.
- Implement RESTful APIs and ensure seamless integration between components.
Collaboration & Leadership:
- Work closely with product owners, business analysts, and DevOps teams.
- Mentor junior developers and data engineers.
- Participate in agile ceremonies, code reviews, and design discussions.
Requirements
- Primary Skil: Hadoop ecosystem (HDFS, Hive, Spark),PySpark,Python,Apache Kafka
- Secondary: UI Angular.
- Experience: Minimum 9 years, 1. Strong experience with Hadoop ecosystem (HDFS, Hive, Spark).
- Proficiency in PySpark for distributed data processing.
- Advanced programming skills in Python.
- Hands-on experience with Apache Kafka for real-time streaming.
- Frontend development using Angular (TypeScript, HTML, CSS).
Architectural Skills:
- Expertise in designing scalable, secure, and high-performance systems.
- Familiarity with microservices, API design, and cloud-native architectures.
Additional Skills:
- Knowledge of CI/CD pipelines, containerization (Docker/Kubernetes).
- Exposure to cloud platforms (AWS, Azure, GCP).
Education:
Bachelors or Masters degree in Computer Science, Engineering, or related field.
Experience:
9+ years in software development, with at least 4 + years in architecture and Big Data technologies.
Preferred Qualifications:
- BFSI domain experience or large-scale enterprise systems.
- Understanding of data governance, security, and compliance standards.
Soft Skills:
- Strong analytical and problem-solving abilities.
- Excellent communication and leadership skills.
- Ability to thrive in a fast-paced, agile environment.