Big Data Engineer Spark (GCP)
Role details
Job location
Tech stack
Job description
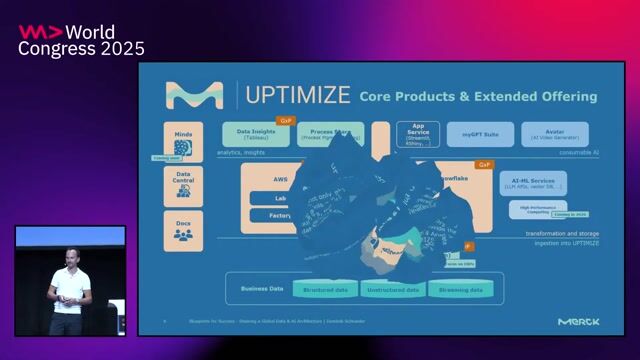
We have an immediate need for a Big Data Engineer ,Spark with our client. This role focuses on building and optimizing large-scale data processing solutions using PySpark and Google Cloud Platform. The engineer will work closely with onshore and offshore teams, gather requirements, and deliver scalable big data pipelines in a hybrid onsite environment.
Requirements
Strong experience with PySpark and GCP, along with solid understanding of distributed data processing and data engineering best practices. Candidates should possess excellent communication skills, the ability to interact directly with business stakeholders, and experience coordinating work across offshore teams.
Benefits & conditions
Step into a high-visibility leadership role at a premier law firm where you'll oversee critical accounting operations, command a competitive $300K-$350K package, drive strategic fi…
- 22 days ago