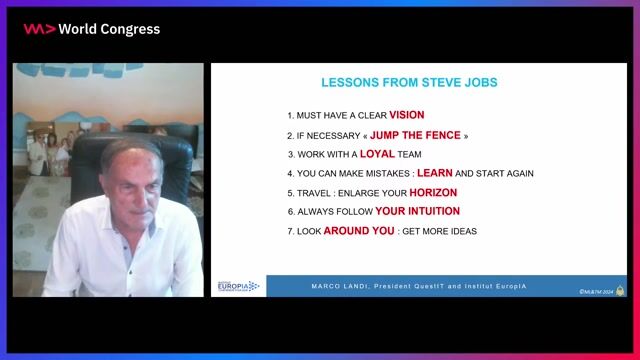
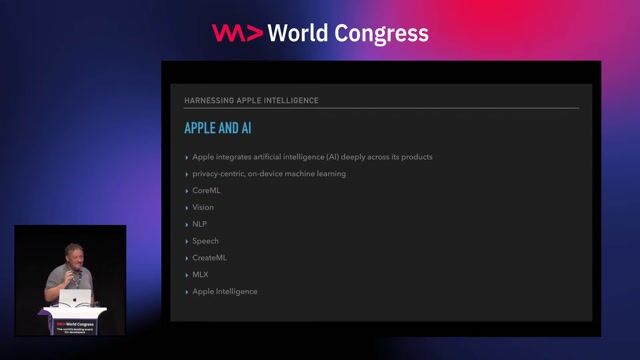
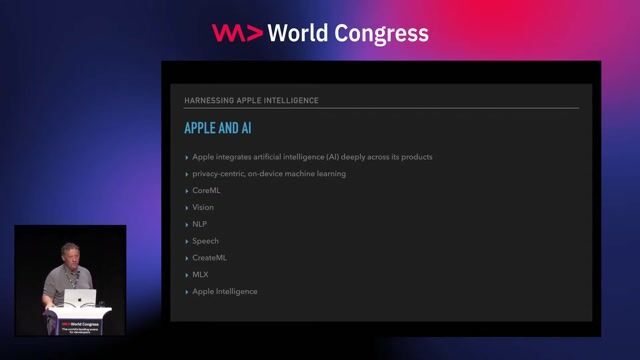
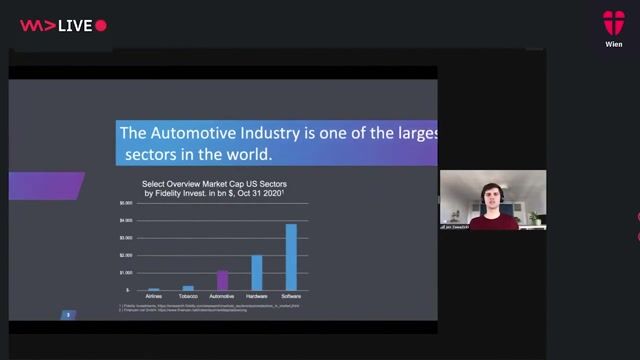
Staff Machine Learning Engineer, Apple Services Engineering
Role details
Job location
Tech stack
Job description
The Staff Machine Learning Engineer - Multimodal Generation & Post-Training will be a senior individual contributor on a small, applied ML team focused on production multimodal systems. The role will lead fine-tuning and adaptation of diffusion and emerging video models, as well as post-training of small and medium LLMs for captioning, moderation, and retrieval-friendly descriptions.
The engineer will design data and evaluation workflows that use our large archive of weakly labeled music, podcast, film, TV, and short-form content to drive measurable quality and efficiency improvements. The role includes close collaboration with partner infra teams for model serving and with adjacent product and research groups to bring new capabilities into production.
Requirements
- Master's degree in Computer Science, Electrical Engineering, or a related technical field, or equivalent practical experience.
- 5+ years of hands-on industry experience building and shipping machine learning systems to production.
- Proven experience training and fine-tuning diffusion or other image/video generative models, including adapter-based methods such as LoRA.
- Proficiency in Python and at least one major deep learning framework such as PyTorch.
- Experience designing and operating ML pipelines for noisy or weakly labeled data, including offline evaluation and monitoring in production.
- Strong software engineering skills, including code quality, experimentation discipline, and debugging/profiling of model performance., * PhD in Computer Science, Machine Learning, or a related technical field.
- 8+ years of industry experience with production multimodal systems spanning image, audio, and/or video.
- Deep expertise with diffusion and video generation techniques (e.g., ControlNet/IP-Adapter, temporal consistency methods, sampling and latency optimization).
- Experience with PEFT/QLoRA and post-training approaches such as DPO or related preference-based methods for small and mid-sized LLMs.
- Background in ASR/VAD/diarization, OCR, multimodal retrieval, or face recognition with fine-grained temporal alignment.
- Familiarity collaborating with infra/platform teams on model serving (e.g., batching strategies, quantization, observability) and translating requirements into reliable production deployments.
- Demonstrated ability to define metrics, build evaluation harnesses, and communicate results clearly to cross-functional partners.
- Track record of publications, patents, or open-source contributions in relevant areas of machine learning or multimodal modeling.