Data AI Engineer with Vector Databases
Role details
Job location
Tech stack
Job description
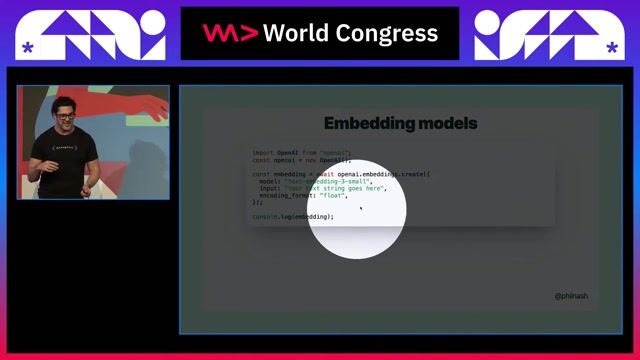
Design and build ETL/ELT pipelines and data processing workflows Develop batch and real-time data pipelines using modern frameworks Work with Python and SQL for data transformation and analytics Implement GenAI data architectures, including RAG pipelines and vector indexing Manage and optimize Vector Databases for embedding storage and similarity search Build secure data solutions on AWS, ensuring data quality and compliance Support analytics, reporting, and data modernization initiatives
Requirements
Strong experience in Python and SQL Hands-on experience with ETL/ELT and data pipelines Mandatory: Experience with Vector Databases Experience with GenAI / LLM frameworks (LangChain or LangGraph) Experience with Big Data frameworks (Apache Spark, Apache Kafka) Workflow orchestration using Apache Airflow Experience with data platforms like Databricks or Snowflake AWS services: S3, Glue, Redshift
Nice to Have: Experience with ML frameworks (Scikit-learn, PyTorch) Knowledge of RAG architectures and embedding pipelines Experience in financial services / fintech environments