This is the accompanying post to the talk Chris Heilmann gave at AgentCon in Berlin on 19/05/2026, you can also see the slides and listen to it in this screencast:
Thirty years of developer shortcuts, bloated JavaScript, and inaccessible HTML have left AI agents scraping the same mess humans always complained about. One veteran developer’s case for doing it right, finally.
I have been a web developer since 1996. Back then, HTML was a revelation — a way of describing what the browser should do rather than painting with code. Browsers were unreliable, so we hacked around them. We used tables for layout. We used spacer GIFs. We did whatever it took. And every time I advanced in my career, the thing that made me most happy was not writing new code. It was deleting the old stuff we no longer needed.
That instinct to simplify — to get rid of what shouldn’t be there — is what this talk is really about. Because right now, the AI moment we’re all living through is being built on top of a web we’ve spent decades making worse. And the bill is coming due.
The Programmable Web, Remembered
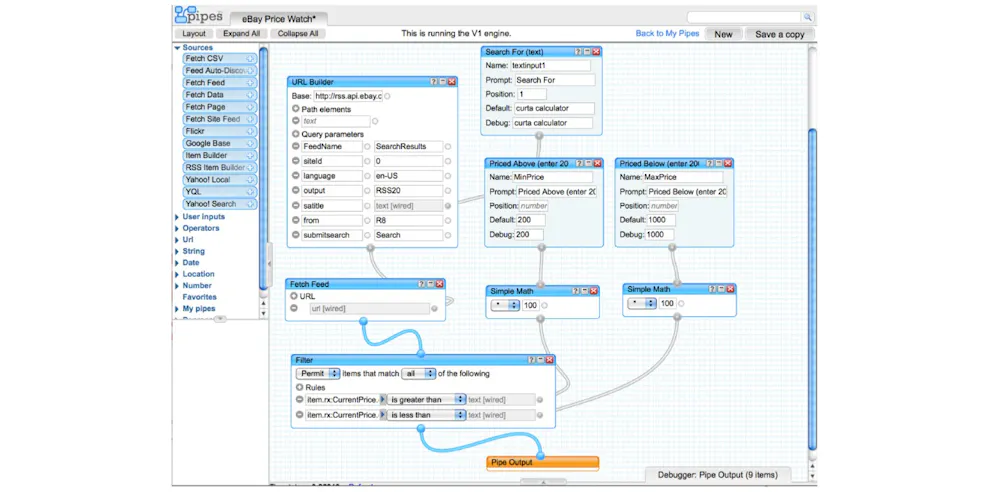
Before we talk about agents, let’s go back. In 2006, Yahoo shipped something called Yahoo Pipes. It looked, now that I think about it, remarkably like the agentic workflow tools people are excited about today — drag-and-drop connectors between RSS feeds, HTML pages, XML outputs, and JSON sources. You could pipe the web’s data through a visual program and get answers out.
“We were using the web as a database in 2006. We invented a whole query language for it. Sounds familiar? It was great. It was actually wonderful.”
We went further. We built YQL — the Yahoo Query Language — a SQL-like syntax that let you query Microsoft Bing, Yahoo Search, and Google in a single statement. It could scrape, aggregate, and return structured results from the open web. It was AI-agent behaviour, just in 2006.
I was so excited about this idea of the web as a queryable data source that I wrote a book about it. By the time it was published, every API I’d written about had been shut down. My total income from it was about $23. I only wrote it so my parents would believe I had a real job. Books don’t make money. The workshops around them do. But I digress.
What Agents Actually Do (And Why It Costs So Much)
An agent, when you strip away the magic, fetches resources and calls tools to get a job done. It pulls data from the web, a service, or a database. It processes and compares that data. It then calls further tools to transform or act on what it found. Both steps can be expensive — in compute, in tokens, in electricity.
The reason it is so expensive is largely our fault. The web was supposed to be the greatest publishing platform ever invented. Instead, we buried the content under tonnes of JavaScript and structural noise.
| Metric | Figure |
|---|---|
| Median homepage size | 2.3 MB |
| Most JavaScript on a single site | 498 MB |
| JavaScript loaded but unused | 60–70% |
The Web Almanac documents this every year. To a human, a 2.3 MB homepage is a slow page. To a scraper or an agent, it’s a job — one that requires downloading every byte, executing the JavaScript to reveal content that wasn’t in the HTML, and then finding the one paragraph that was actually relevant.
The situation has become so broken that many people now run Playwright to take screenshots of websites, then OCR those screenshots, rather than reading the HTML. Let that sink in. We built a text medium and made it so unusable that the best strategy is to photograph it and read the photograph.
Accessibility Is Not a Separate Problem
A scraper tool is very much like a user who cannot see. It cannot glance at a page and immediately discard the ads, the autoplay video, the cookie banner. A human eye does that in milliseconds. A bot has to be explicitly taught — or it processes everything.
The WebAIM Million report checks the top one million websites for accessibility failures each year. The results have barely moved since 2019:
| Failure | Rate |
|---|---|
| Low contrast text | 83% |
| Missing image alt text | 54% |
| Empty links | 43% |
| Missing form labels | 36% |
| Empty buttons | 28% |
Low contrast text is bad for humans with poor vision and for OCR alike. Missing alt text means an agent has no idea what an image contains. Empty links and unlabelled buttons leave a scraper — like a screen reader user — with no information about what interaction is possible.
These aren’t arcane standards violations. They are the same things that make a page readable and parseable by any automated system. Accessibility and agent-friendliness are the same problem.
The CMS Already Solved This. We Just Didn’t Notice.
Here is something that stopped me cold when I first read Terence Eden’s blog post about it: WordPress, which powers around 60% of the web, already ships a full JSON API for every post on every site. No scraping needed. You change the URL to the WP JSON endpoint and you get structured content directly.
I didn’t have to do anything to have this on my own blog. I didn’t even know I had it until I read Terence’s post. It’s there on every WordPress site, discoverable from the robots.txt, ready to be used. Sixty percent of the web is just waiting to be queried properly.
Most CMS systems work this way. They hold content in structured form — markdown, clean text, metadata — and expose it through APIs that return JSON, oEmbed, ActivityPub, and more. There’s even a text-only format, essentially a pre-built clean feed for bots and agents. If you know where to look, the web is already far more structured than it appears from the HTML layer.
LLMs Learned From the Worst of the Web
The models we’re all building on were trained largely on the output of the messy web we made. Stack Overflow, for example, tends to surface the most-upvoted answer first — which is usually the one that explains the how, not the why. Do this, don’t think about it. LLMs learned from that top answer, not from the nuanced fourth or fifth response further down the thread.
The evidence is visible in what they generate. GitHub’s research into a general-purpose accessibility agent found that even the best current models produce accessible HTML only about 25% of the time without intervention. The most expensive model was not the best performer. These models were not optimised for this, and it shows.
GitHub’s solution was instructive: rather than relying on a single agent to get it right, they built a review loop — sub-agents that check the original agent’s output against WCAG guidelines and refine it. No accessibility audit works on the first pass. The same is true of generated code.
What You Should Actually Do
HTML is still the best way to describe content and link resources together. It is small, cheap, readable by humans and machines, and it has been documented since 1995. A few concrete steps worth taking:
Use semantic HTML. Headings, sections, article elements, main. Not twenty thousand divs with five thousand classes. Structure tells a parser — human or machine — what something is for.
Label everything interactive. Buttons, inputs, links. A button that says “button” is useless. A button that says “submit this form” is helpful to a screen reader, a scraper, and an agent trying to understand what it can do on the page.
Give images alt text that earns its place. Not “image of orange.” Why is the image there? What does it add? If you can’t answer that, don’t use the image.
If you generate content, generate accessible content. Build the audit into the creation loop. The best time to catch a missing label is when you write the HTML, not six months later when a user reports a bug.
Use what the web already gives you. If you’re scraping a WordPress site, check the JSON API first. If you’re building an agent that reads web content, look for meta descriptions, structured data, and sitemaps before you download the full page. They are there. They are free. They will save you tokens.
“If you want to save tokens, structure your output. Not beautiful nonsense — structured output that tells a reader, human or bot, exactly what something is and why it’s there.”
The web was supposed to be a platform anyone could publish on and anyone — or anything — could read. We spent twenty years making that harder than it needed to be. We have a second chance now, because the AI moment is forcing the question: does this content actually communicate anything, or is it just visual noise?
HTML is still the answer. It always was.
Adapted from a talk at AgentConf, Berlin. Resources referenced: MCP Mashups by Angie Jones, the Web Almanac 2025, the WebAIM Million report, GitHub’s accessibility agent research, and The Unreasonable Effectiveness of HTML.