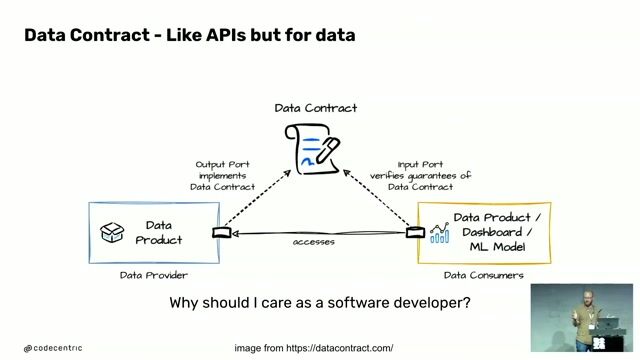
DATA ENGINEER (Data Science & Big Data Analytics)
Role details
Job location
Tech stack
Job description
· Design and deploy data pipelines for bringing data and control metadata lineage from different source systems to a data warehousing system, including queue management and real-time data processing.
· Architect reusable software practices using state of the art orchestration systems such as Airflow or Dagster and containerization stack such as Docker or Kubernetes.
· Deploy data sharing and cataloguing existing software tools to enable Data Spaces through standard building blocks from IDSA, Gaia-X and Fiware.
· Contribute to Machine Learning projects by adopting technologies for data storing, serving and versioning capabilities from blob-Storage to traditional SQL solutions and NoSQL.
· Assist the unit in multi-cloud deployments (Amazon Web Services, Azure and Google Cloud Platform).
· When applicable, deploy and design Big Data Architectures including batch and streaming paradigms such as Flink, Spark Structured Streaming, Kafka, and the Hadoop Ecosystem.
· Project management and technical lead in EU funded and private projects. Writing proposals for Horizon Europe calls (excellence, task description…)
Requirements
· MsC in Computer Science. Other technical background will also be considered (Engineer, Mathematics, Physics, etc.) and PhD or Masters in this field will be highly valuated.
Experience
· Database Systems (MySQL, PostgreSQL, MongoDB, ElasticSearch, Cassandra DB, Redis)
· Implementation of data catalogues (CKAN), data brokers and data connectors (DSSC, Eclipse, Fiware)
· Airflow and Python based E(L)TL data pipelines.
· Cloud providers technological stack (Serverless functions, Virtual Computing Resources, Storage).
· Software patterns best practices as well as knowledge from Data Mining and Machine Learning.
· Languages and programming tools (Python, Java, Scala, SQL, C/C++, Git, Docker)
· DevOps knowledge and experience in Linux is a big plus, specially deploying and maintaining big data infrastructures using Ambari or Ansible.
· Interest in Research, Innovation & Patent Publication, Conference Presentations, Prototyping, Full Lifecycle Product Development.
Languages
· Excellent written and oral communication skills in English.
· Catalan and/or Spanish would be desirable.
Benefits & conditions
- Hybrid work (home office/ work in the office).
- Flexible Schedule.
- Shorter workday on Friday and Summer Schedule.
- Flexible remuneration package (health insurance, transport, lunch, studies - training and kindergarten).
- Eurecat employees can join the Eurecat Academy courses.
- Language courses (English, Catalan and Spanish).