Senior Data Engineer
Moonfare GmbH
2 days ago
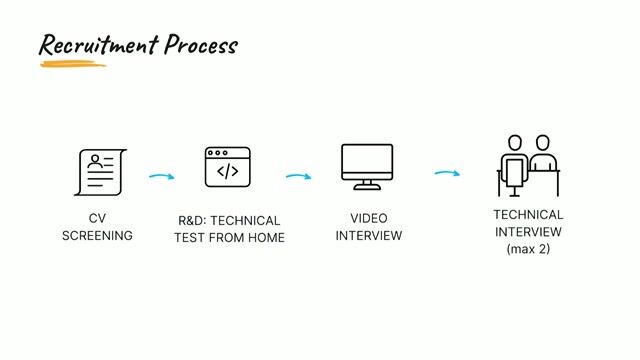
Role details
Contract type
Permanent contract Employment type
Full-time (> 32 hours) Working hours
Regular working hours Languages
English Experience level
SeniorJob location
Tech stack
Amazon Web Services (AWS)
Data analysis
Bash
Cloud Computing
Computer Programming
Continuous Integration
Data Cleansing
Data Governance
Data Infrastructure
Data Systems
Data Warehousing
Relational Databases
Hadoop
Identity and Access Management
Python
Performance Tuning
SQL Databases
Tableau
Data Processing
Data Classification
Spark
Data Lake
Kubernetes
Real Time Data
Data Pipelines
Docker
Job description
As an integral part of our team, you will drive the day to day operation of Moonfare, which in turn will influence how our product evolves and how customers interact with our product. You will be joining a small team of Data Engineers, ensuring that real-time data is available to our analysts through the design and development of robust data pipelines. As our business is rapidly expanding, so are our data sources, so you will be responsible for initiating scalable and streamlined solutions to provide reliable data to the business in a secure and timely manner.
You will:
- Manage and scale Moonfares's BI data infrastructure by developing and maintaining our data pipelines from ingestion through to storage
- Model data using solid data lake/warehouse concepts and optimize performance(partitioning, file formats, performance tuning)
- As a central figure of a small team, you will champion standards, processes and best practices in your area
- implement least-privilege IAM, encryption, data classification, PII handling, and auditability and contribute to data governance policies
- Conduct data analysis experiments, providing bespoke solutions to our stakeholders giving them the information they need to succeed
- collaborate with analysts and domain stakeholders to translate requirements into robust data solutions, review code, and mentor peers
- High quality data is at the core of Moonfare's success, you will help us continue our standards through data cleansing, coding consistency and data availability
- We want to hear your ideas! You will bring all of your previous experiences and thoughts to the table and help us bring in new tools, topics and methodologies to the BI Team
Requirements
Do you have experience in Tableau?, * 5+ years working experience as a Data Engineer, ideally having worked within a regulated financial services environment
- You are an expert in designing and developing robust Data Pipelines using technologies such as Apache Spark,Hadoop ecosystem with a deep understanding of data processing
- You have a strong background in cloud infrastructure (especially AWS) and hands-on experience of data lakes and modern data warehouses, including familiarity with orchestration, security, and network
- You have proven programming experience with Python and Scala and you are also happy to review code
- You work with relational databases, data warehouses and advanced SQL queries
- You have experience with CI/CD & bash scripting and deployment/release best practices
- You have practical experience with Docker and working knowledge of Kubernetes
- You have working knowledge of DBT (models, tests, documentation) and a general understanding of Tableau or similar BI tools
- You collaborate with analysts and other stakeholders to understand data requirements and provide efficient data solutions
- You contribute to the development and maintenance of data governance and security practices
- Excellent written and verbal communication skills in English and have a clear and adaptive communication style
- You are solution-oriented and have excellent attention to detail
- You have creative problem-solving abilities and a passion for data
About the company
Moonfare delivers what few others can: the highly sought-after funds and hidden-gem investments that go beyond what most private banks offer. Every opportunity is subjected to a ruthless vetting process; the bar is unforgivingly high. The result? Institutional-quality portfolios for investors who demand more.
Our team combines finance veterans with talent from tech, consulting, law and industries you'd never expect. Headquartered in Berlin, we operate from eight offices across Europe, the US and Asia.
If you're ready to build what's next in private markets, let's talk., Our Values:
* Our clients come first, Moonfare comes second, and we prioritise ourselves third - Client-Centric Focus. Putting clients first means creating value for them is essential. Placing Moonfare second signifies that our individual professional future at Moonfare depends on the company's commercial success. Prioritising ourselves third reflects our humility in putting clients and Moonfare before personal interests.
* We pursue excellence and honor our promises - Commitment to Excellence. We hold ourselves to the highest standards, taking responsibility for our failures, and celebrating our successes. We commit to deadlines and stick to them and we learn from our mistakes.
* We are here to win and to celebrate our collective achievements - Win together. We are mission-focused and think and act like owners. We exemplify the attitude we expect and each of us commits to do what it takes to succeed.
* We foster personal growth but each of us earns our place as a Moonfarian through merit - Growth and Merit. We hire, retain, and develop exceptional people and invest in empowering them to excel. We must all earn our place at the table every day.
We understand the important role that diversity plays in our success. Different backgrounds, experiences and ideas push us further and raise the bar. We're committed to developing an inclusive and safe culture where everyone - regardless of colour, race, religion, sex, origin, sexuality, disability, marital status, citizenship or gender identity - knows that they are an integral part of the team and can bring their full potential to their work.
* Minimum investments vary according to jurisdiction.