Site Reliability Engineer gesucht in Berlin
IONOS SE
Berlin, Germany
1 month ago
Role details
Contract type
Temporary contract Employment type
Full-time (> 32 hours) Working hours
Regular working hours Languages
English, GermanJob location
Berlin, Germany
Tech stack
Proxmox
Amazon Web Services (AWS)
Bash
Cloud Computing
Code Review
Continuous Integration
Dynamic Host Configuration Protocol
Software Debugging
Linux
DevOps
RAID
Distributed Systems
DNS
Infrastructure as a Service (IaaS)
InfiniBand
Virtual Private Networks (VPN)
Python
Logical Volume Manager
OpenStack
Platform as a Service (PAAS)
Performance Tuning
Quick EMUlator (QEMU)
Remote Direct Memory Access
Ansible
Prometheus
Wide Area Networks
Ceph
Data Logging
Saltstack
Grafana
Perf (Linux)
Gitlab-ci
Script Language
Kubernetes
Terraform
Docker
Go
Job description
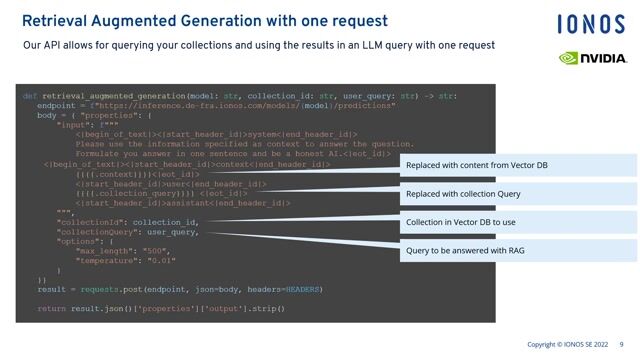
Wir suchen einen hochqualifizierten und erfahrenen Site Reliability Engineer, der unser Team im 24/7-Shift unterstützt. Die SRE-Abteilung L2 betreibt sämtliche IONOS-Cloud-IaaS- und PaaS-Dienste. Als Site Reliability Engineer bist Du für die Stabilität, Sicherheit und Performance unserer komplexen, verteilten Systeme verantwortlich. Du arbeitest eng mit den Entwicklungsteams zusammen, um skalierbare und zuverlässige Infrastrukturen zu entwerfen, zu implementieren und zu betreiben sowie Prozesse zu automatisieren und zu optimieren., * Technischer Level-2-Support mit direktem Kundenkontakt.
- Pflege von Monitoring-, Logging- und Alerting-Lösungen (z. B. Prometheus, Grafana, Loki) zur proaktiven Erkennung von Problemen im Schichtbetrieb und Mitwirkung bei der Lösung komplexer Issues in verteilten Systemen.
- Fehlersuche in Netzwerken (LAN/WAN/VPN, DNS, DHCP) und Speichersystemen (File/Object/Block); Bereitstellung und Betrieb hochverfügbarer Services auf Linux und Kubernetes (Helm-Charts).
- Aufbau und Pflege von Infrastructure-as-Code, Automatisierung und Playbooks mit Ansible, Terraform, GitLab CI/CD, Argo CD sowie Skriptsprachen wie Bash, Python und Go.
- Zusammenarbeit mit Entwicklungsteams zur Verbesserung von Prozessen und Deployments sowie zur reibungslosen Integration neuer Services und Applikationen in unsere Cloud- und Kubernetes-Umgebung.
- Gewährleistung eines stabilen und sicheren Plattformbetriebs, inklusive End-to-End-Incident-Management von der ersten Analyse über die Lösung bis hin zur Nachbearbeitung im Rahmen des Problem-Managements., * An einigen Standorten eine bezuschusste Kantine und verschiedene kostenfreie Getränke.
- Moderne Büroflächen mit sehr guter Verkehrsanbindung.
- Diverse Mitarbeiterrabatte für Aktivitäten und Produkte.
- Mitarbeiterevents wie Sommer- und Winterfeiern, sowie Workshops.
- Zahlreiche Weiterbildungs- und Entwicklungsmöglichkeiten.
- Verschiedene Gesundheitsangebote, wie Sport- und Gesundheitskurse.
Requirements
- Bereitschaft, in einem 24 × 7-Schichtmodell zu arbeiten (Nacht-, Wochenend- und Feiertagsdienste) und dabei ein starkes Problem-Lösungs- und Troubleshooting-Mindset mitzubringen.
- Mehrjährige Erfahrung als Site Reliability Engineer oder in einer verwandten Rolle (Linux-Systemadministrator, Platform Engineer, DevOps/Infrastructure Engineer, Full-Stack-Developer).
- Fundierte Kenntnisse in Automatisierungstools (z. B. Ansible, SaltStack), Monitoring- und Observability-Tools (Prometheus, Grafana, Loki) sowie Logging- und Alerting-Lösungen (ELK-Stack).
- Erfahrung mit virtualisierten Umgebungen (QEMU/KVM, OpenStack, Proxmox), Cloud-Storage-Technologien (File, Object, Block) und sicherer Umgang mit Docker & Kubernetes.
- Sehr gute Kenntnisse in mindestens einer Programmiersprache oder Skriptsprache (Go, Python, Bash) für Automatisierungs- und Monitoring-Aufgaben.
- Erfahrung im Code-Management (Merge-Conflicts, Feature-Branches, Merge-Requests, CI/CD) ist von Vorteil.
Nice-to-have:
- Erfahrung mit RDMA, InfiniBand und RoCE-Protokollen.
- Tiefe Kenntnisse in Linux MD RAID (mdadm, sedadm) und LVM.
- Expertise in Linux-Performance-Tuning und Netzwerk-Stack-Debugging (ethtool, perf, tcpdump, ibstat, ibtop).
- Praxis mit S3, Ceph und software-definierten Netzwerken.
- Erfahrung mit etablierten Software-Entwicklungspraktiken (Code-Reviews, Build-Prozesse, Packaging, Testing).
Sprachkenntnisse: Fließend in Deutsch und Englisch (mindestens B2 nach dem CEFR-Standard).
About the company
Bei IONOS arbeitest Du bei dem führenden europäischen Anbieter von Cloud-Infrastruktur, Cloud-Services und Hosting-Dienstleistungen partnerschaftlich mit unterschiedlichen Teams zusammen. Wir bieten Dir eine Perspektive in einer der zukunftssichersten Branchen. Uns zeichnen offene Arbeitsstrukturen, Duz-Kultur und flache Hierarchien mit unvergleichlichem Team-Spirit aus. Wir sind fest davon überzeugt, dass Job und Spaß vereinbar sind und bieten Dir hierfür das entsprechende Umfeld. Bei ständigem Wachstum sind wir stets auf der Suche nach neuen Kolleginnen und Kollegen. Werde Teil von IONOS und lass uns gemeinsam wachsen., IONOS ist der führende europäische Digitalisierungs-Partner für kleine und mittlere Unternehmen (KMU). IONOS hat mehr als sechs Millionen Kundinnen und Kunden und ist mit einer weltweit verfügbaren Plattform in 18 Märkten in Europa und Nordamerika aktiv. Mit seinen Web Presence & Productivity-Angeboten agiert das Unternehmen als "One-Stop-Shop" für alle Digitalisierungs-Bedürfnisse - von Domains und Webhosting über klassische Website-Builder und Do-It-Yourself-Lösungen, von E-Commerce bis zu Online-Marketing-Tools. Darüber hinaus bietet IONOS Cloud-Lösungen für Firmen, die im Zuge der Weiterentwicklung ihres Geschäfts in die Cloud wechseln möchten.