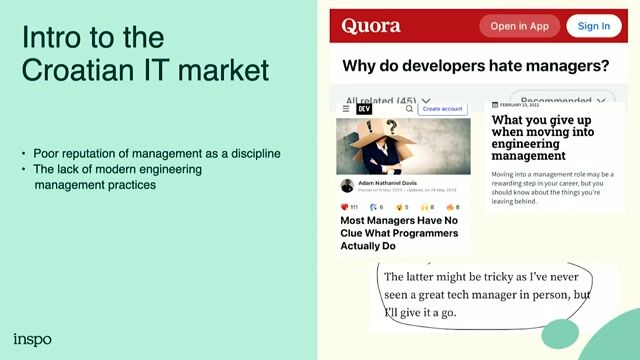
INGENIEUR ACQUISITION & TRAITEMENT DE DONNEES
Role details
Job location
Tech stack
Job description
? Faire l?analyse technique et la conception du ou des logiciels à réaliser.
? Réaliser les logiciels dans le/les langage(s) le plus approprié.
? Concevoir et implémenter des procédures de test.
? Déployer les logiciels (paquets).
? Rédiger les spécifications, documentations techniques et utilisateurs.
LIVRABLES
Analyse technique et conception (spécifications techniques, architecture logicielle) ;
Code source des logiciels développés ;
Procédures et scripts de test ;
Packages déployables ;
Documentation technique et utilisateurs
Profil & Exigences techniques : ? Maîtrise approfondie des concepts de traitements de données scientifiques :
? Développement et implémentation d'algorithmes pour l'analyse d'images scientifiques (ex: détection de features, segmentation, reconstruction tomographique, analyse de diffraction/diffusion).
? Application et développement de méthodes de calculs statistiques (ex: ajustement de
modèles, analyse d'erreurs, tests d'hypothèses, classification) et mathématiques (ex:
transformées de Fourier, algèbre linéaire, optimisation numérique) appliquées aux
données expérimentales.
? Compréhension des formats de données scientifiques (HDF5, NeXus, TIFF, etc.) et
des bibliothèques associées.
? Expérience dans le séquencement et l?orchestration de traitements de données
(Apache Airflow, etc.)
? Expérience dans la gestion et le traitement de volumes importants de données (Big
Data) et dans l'optimisation des pipelines de traitement.
? Connaissance et utilisation d'outils de réduction et d?analyse de données du monde
open source : ? ImageJ/Fiji : Pour le traitement et l'analyse d'images.
? Python/Jupyter Notebooks/JupyterLab : ? Pour l'analyse interactive, la visualisation et le prototypage.
? Bibliothèques spécialisées : Connaissance de bibliothèques dédiées à des techniques
d'analyse spécifiques (ex: SPEC, Lima, Bliss, Sardana, TANGO Controls).
? Optionnellement, mais fortement apprécié, maîtriser les méthodes de parallélisation de
codes pour le calcul intensif (HPC) : ? Parallélisation multi-threading (OpenMP).
? Calcul distribué (OpenMPI, ZeroMQ, gRPC).
? Programmation sur GPU (CUDA/OpenCL, OpenACC).
? Compréhension des architectures de calcul parallèle et des problématiques de
scalabilité., ? Maîtrise approfondie des concepts de traitements de données scientifiques :
? Développement et implémentation d'algorithmes pour l'analyse d'images scientifiques (ex: détection de features, segmentation, reconstruction tomographique, analyse de diffraction/diffusion).
? Application et développement de méthodes de calculs statistiques (ex: ajustement de
modèles, analyse d'erreurs, tests d'hypothèses, classification) et mathématiques (ex:
transformées de Fourier, algèbre linéaire, optimisation numérique) appliquées aux
données expérimentales.
? Compréhension des formats de données scientifiques (HDF5, NeXus, TIFF, etc.) et
des bibliothèques associées.
Requirements
? Expérience dans le séquencement et l?orchestration de traitements de données
(Apache Airflow, etc.)
? Expérience dans la gestion et le traitement de volumes importants de données (Big
Data) et dans l'optimisation des pipelines de traitement.
? Connaissance et utilisation d'outils de réduction et d?analyse de données du monde
open source : ? ImageJ/Fiji : Pour le traitement et l'analyse d'images.
? Python/Jupyter Notebooks/JupyterLab : ? Pour l'analyse interactive, la visualisation et le prototypage.
? Bibliothèques spécialisées : Connaissance de bibliothèques dédiées à des techniques
d'analyse spécifiques (ex: SPEC, Lima, Bliss, Sardana, TANGO Controls).
? Optionnellement, mais fortement apprécié, maîtriser les méthodes de parallélisation de
codes pour le calcul intensif (HPC) : ? Parallélisation multi-threading (OpenMP).
? Calcul distribué (OpenMPI, ZeroMQ, gRPC).
? Programmation sur GPU (CUDA/OpenCL, OpenACC).
? Compréhension des architectures de calcul parallèle et des problématiques de
scalabilité.