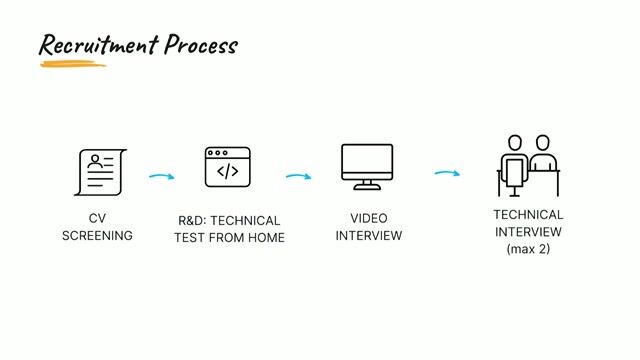
Data Engineer - Confirmé.e
Role details
Job location
Tech stack
Job description
Au sein de notre practice Data & AI, tu travailles conjointement avec les Data Scientists, Data Engineers, MLE/MLOps engineer déjà en poste et tu es impliqué.e dans la prise de décisions liée aux solutions Data et à son évolution.
A cet effet, tu es en charge de :
- Contribuer au développement de notre offre Data et à l'industrialisation de plateformes data pour nos clients
- Comprendre, analyser et proposer des solutions techniques répondant aux besoins des Plateformes digitales et des projets internes
- Définir l'architecture logiciel ETL / ELT en collaboration avec vos pairs
- Travailler la donnée sous toutes ses formes (stockage, élaboration de modèles, structuration, nettoyage)
- Rédiger de la documentation technique (diagrammes UML, documentation d'API, …)
- Partager votre savoir-faire entre les différents membres de l'équipe
- Concevoir et développer des connecteurs entre les sources de données (internes et/ou externes) et la plateforme
- Concevoir et développer des pipelines de traitements de données (batch et/ou temps réel) dans un environnement Big Data
- Assurer une veille technologique et savoir mener à bien un projet de R&D
Tu assures en autonomie les missions suivantes en interne ou auprès de nos clients grands comptes :
- Cartographier des données et des flux de données
- Implémenter des algorithmes d'analyse de données pour l'industrialisation
- Collecter, consolider et modéliser de gros volumes de données (Big Data, Data Warehouses, Data Lakes)
- Développer et automatiser des flux de données et leurs visualisations en dashboards, reporting
- S'assurer de la scalabilité, sécurité, stabilité et disponibilité des données de la plateforme
- Analyser les données web pour répondre aux questions métiers et participer à la construction de l'architecture Big Data
- Mettre en place du séquencement et de la supervision des flux précitées en gérant les cas limites
Requirements
Bon niveau en développement: :
- De script ETL : Python (Pandas, API Rest, FaaS), Java (ex Kafka Connect, SOAP), Spark (PySpark, Databricks, Delta Lake)
- De script ETL : DBT (ex. Snowflake, PostgreSQL)
- Connaissance conception et administration d'entrepôt de données : Snowflake, Big Query, PostgreSQL
- LakeHouse : Delta LakeConnaissance message broker, RabbitMQ, Kafka
- Compétences cloud : Kubernetes, Conteneurisation, Fournisseur cloud (AWS, GCP ou Azure), Infrastructure As Code (Terraform)
- Expérience d'architecture et de dimensionnement d'une architecture cloud via des services managés
- Cartographie des données, Diplômé·e d'études supérieures dans le système d'information, computer sciences, big data (école d'ingénieurs, école spécialisée ou équivalent universitaire), tu justifies d'au moins 3 ans en Data engineering.
Tu as une expérience significative sur la mise en place de pipelines complets de valorisation de données massives, de la collecte à la mise à disposition d'applications en passant par le traitement.
La maîtrise de l'anglais est appréciée.
Certification·s appréciée·s : GCP Professionnal Data Engineer OU Azure Data Engineer Associate OU AWS Solution Architect.
Tu es passionné·e par ton métier et aimes le faire partager.