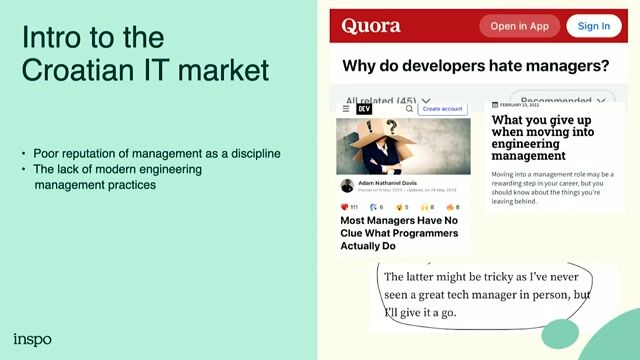
Senior Data Engineer
Westhouse Consulting GmbH
6 days ago
Role details
Contract type
Permanent contract Employment type
Full-time (> 32 hours) Working hours
Regular working hours Languages
German Experience level
SeniorJob location
Tech stack
API
Airflow
Amazon Web Services (AWS)
Amazon Web Services (AWS)
Data analysis
Cloud Computing
Continuous Delivery
Continuous Integration
ETL
Data Structures
Python
Scrum
Power BI
Software Engineering
SQL Databases
Tableau
Spark
Boto3
GIT
Pandas
PySpark
Amazon Web Services (AWS)
Docker
Job description
- Beratung bei der Weiterentwicklung des cloudnativen Backends, dazu gehören die Konzeptionierung, Umsetzung und Dokumentation von neuen Features
- Erstellung von Datenvisualisierungen und -berichten Automatisierung von Datenprozessen Analyse und Beurteilung von Daten und Entwicklung von Daten Pipelines basierend auf der bestehenden Architektur und dem aktuellen Zonen-Konzept (raw - trusted - refined)
- Data Exploration von neuen Datenquellen sowie Implementierung von geeigneten Datenstrukturen
- Fachliche Unterstützung im SCRUM Team, Teilnahme an Refinements, Plannings, Reviews, Retros Erstellung von Daten-Pipelines auf Basis von Python, Apache Spark, PySpark, Pandas, SQL, Boto3 API, SNS, SQS und REST
- Zur Pipeline Erstellung notwendige Implementierung, Konfiguration und Nutzung der serverless AWS-managed Infrastruktur, speziell Glue, Apache Airflow, Batch, S3, Athena und Glue Data Quality
Requirements
- Mindestens 3 Jahre Erfahrung im Bereich der Data Exploration, Analyse und Modellierung sowie in der Qualitätssicherung von Daten (Data Stewardship).
- Mindestens 3 Jahre Erfahrung mit der für die geforderte Pipeline-Entwicklung erforderlichen AWS Cloud Technologien und deren Managed Services
- Projekterfahrung (min. 1 Projekt) bei der Dashboard Entwicklung mit z.B. PowerBi, QuickSight oder Tableau
- Mindestens 3 Jahre Projekterfahrung in der Softwareentwicklung (z.B. GIT, Continuous Integration/Continuous Deployment (CICD)
- Mindestens 5 Jahre Praxiserfahrung in der Entwicklung und Automatisierung von ETL Strecken und der Datenmodellierung mittels der für die geforderte PipelineEntwicklung erforderlichen Tools und Programmiersprachen (SQL. Python,...)
- SOLL-Kriterien:
- Mindestens 1 Projekt: Architekturverständnis der vergleichbaren (serverless) Cloud-Datenplattformen aus Projekterfahrung
- Mindestens 1 Projekterfahrung im Bereich Data Science und der Anwendung bestehender Prognose-/Klassifikations-/Clusteringalgorithmen
- Mindestens 1 Projekterfahrung: Kenntnisse agiler & skalierter Arbeitsmethode
- Mindestens 3 Jahre praktische Erfahrung mit Docker Containern
- Mindestens 2 Jahre Projekterfahrung im Umgang mit typischen Projekten und Daten in der Branche Transport & Logistik, insbesondere im Umgang mit unterschiedlichen Datenformaten, Qualitätseinschränkungen und Verarbeitungsprozessen auf vorgelagerten Data
- Mindestens 1 Projekt: Praktische Projekterfahrung mit AWS Sagemaker