Data Engineer
Role details
Job location
Tech stack
Job description
Analyze & Strategize: Assess client IT landscapes to identify the most effective approaches for building high-quality, scalable data assets.
Consult & Advise: Guide clients on Data Architecture, Data Management, Data Warehousing, and modern platforms like Data Lakes and Data Lakehouses.
Design & Build: Develop and enhance cutting-edge data solutions using technologies such as Hadoop, Snowflake, Exasol, and others.
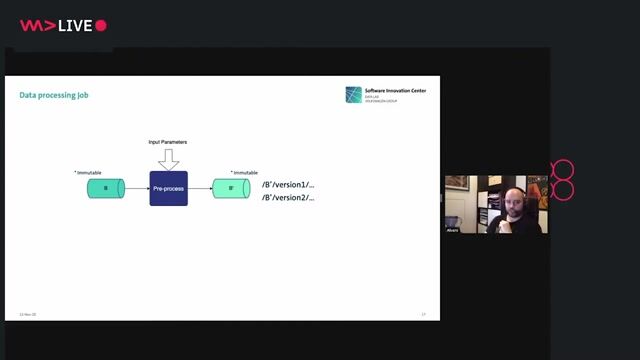
Engineer Data Pipelines: Create and optimize robust data pipelines to ensure reliable and timely data availability.
Stay Ahead of the Curve: Keep up with industry trends and continuously incorporate best practices into your work.
Lead Projects: Depending on your experience, take ownership of initiatives or lead end-to-end projects.
Requirements
Strong Data Knowledge: A deep understanding of modern data architectures, including Data Warehouse, Data Lakehouse, Data Mesh, and Data Fabric-and when to use them.
Hands-On Technical Skills:
Data Tools: Proven experience with open-source tools and platforms like Kafka, the Hadoop ecosystem, and others.
Real-Time Pipelines: Expertise in building real-time data pipelines using technologies such as Flink, Kafka, Spark, or dbt.
Programming Proficiency: Solid skills in Python and Java.
Language Skills: Professional fluency in English.
Mindset: Agile, curious, and passionate about leveraging data to drive impact.
Ready to Make an Impact?, * Apache Kafka
- Data Warehousing
- English
- Hadoop Hive
- Java
- Kubernetes
- Maven
- Spanish
- Spring Boot