Data Engineer (Intermediate Level)
Role details
Job location
Tech stack
Job description
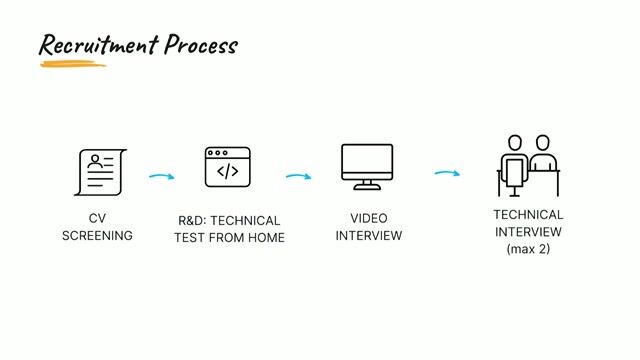
We are seeking a Data Engineer with established commercial experience (intermediate level) to join our growing data infrastructure and research systems team. This role focuses on managing and improving large-scale SQL Server ETL processes that handle GP clinical data for real-world research. This is a hands-on role for a problem-solver who is autonomous in T-SQL and ETL development and is looking to deepen their expertise. You'll work with high-volume datasets, evolving data feeds, and complex import processes, while contributing to our evaluation/expansion into PostgreSQL clustered platforms as an additional environment., * Manage and improve automated SSIS-based ETL pipelines importing data from multiple GP clinical systems (~700 imports/month, 150+ large scripts).
- Continuously adapt import processes to handle changing file formats and evolving specifications.
- Execute data consistency and validation checks across multiple databases.
- Develop and run historic fix scripts to identify and correct data issues.
- Perform general DBA tasks, including backup management, integrity checks, and performance monitoring.
- Confidently handle server-level file operations, including data import/export and directory management.
- Optimise partitioned tables and queries for very large datasets (10 + rows, 50+ TB total).
- Work closely with research and data science teams to ensure data aligns with OMOP CDM and SNOMED CT standards
Requirements
Do you have experience in Time management?, As an intermediate-level engineer, you will already have a strong foundation and be capable of independently managing complex tasks. We are looking for:
- Deep, hands-on expertise in SQL Server development, including advanced T-SQL (stored procedures, functions, complex queries) and experience building/maintaining ETL pipelines, preferably using SSIS or other recognised technology.
- Demonstrable commercial experience (e.g., ~3-6 years) in a data-focused role (Data Engineering, BI Development, Database Administration) working with very large databases (VLDBs).
- Proven experience managing and querying data in complex sectors where data volume and quality are critical (e.g., clinical/health data, finance, insurance, or large-scale e-commerce) preferable at least two different environments.
- A strong command of database optimisation, including query tuning, effective indexing strategies (e.g., clustered, non-clustered, columnstore), and the ability to read and interpret query execution plans to diagnose performance issues.
- Evidence of managing a mature, script-heavy ETL environment and adapting it to new requirements.
- A systematic approach to problem-solving and root cause analysis, particularly for complex data quality and pipeline failures.
- Comfortable with server-level operations, including Windows Server file/directory management and using utilities for data import/export.
- Strong communication skills, with the ability to collaborate effectively with technical, research, and data science teams.
Desirable Skills
- Experience with PostgreSQL or distributed database architectures (e.g. Citus).
- Familiarity with OMOP CDM, SNOMED CT, or clinical research data models.
- Experience building or customising ETL logic in C# or Java.
Future Projects
- Migration of one major research database to a PostgreSQL clustered platform, expanding our data infrastructure rather than replacing SQL Server.
- Development of OMOP-compatible data pipelines to strengthen interoperability and support advanced research workflows.
Benefits & conditions
- 50+ TB of structured research data across multiple SQL Server environments.
- Data collected from GP practices nationwide for medical and population health research.
- Collaborative technical team with a strong emphasis on data quality, performance, and innovation.
- A global research organisation working in partnership with leading pharmaceutical companies and producing high-impact internal research.
Why Join Us
You'll help shape and maintain the data infrastructure underpinning some of the UK's most significant clinical research. This is a hands-on role ideal for a capable data engineer ready to deepen their expertise across large-scale SQL Server systems and emerging PostgreSQL clusters.
Job Types: Full-time, Permanent
Pay: £43,000.00 per year
Benefits:
- Additional leave
- Casual dress
- Company pension
- Cycle to work scheme
- Free flu jabs
- Paid volunteer time
- Sick pay