Data Engineer H/F
Role details
Job location
Tech stack
Job description
Suite à la forte croissance de MP Data et une forte demande de nos clients en Belgique nous recherchons un(e) Data Engineer pour rejoindre notre équipe à Liège., Pipeline Engineering : Concevoir, développer et optimiser des pipelines de données (ETL/ELT) massifs et performants en utilisant principalement Python et PySpark.
- Orchestration : Mettre en place et maintenir des workflows robustes avec Apache Airflow pour garantir l'automatisation et la fiabilité de l'ensemble de la chaîne de données.
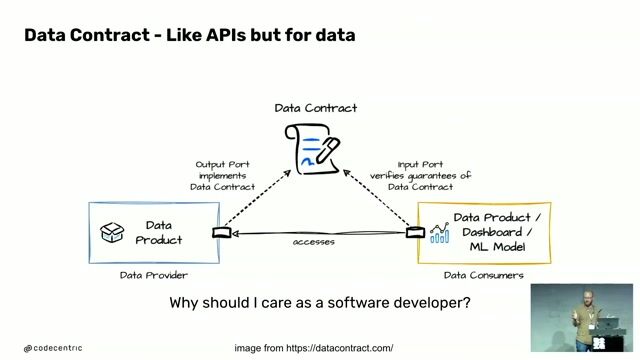
- Architecture Data Mesh : Contribuer activement à la migration et à l'évolution de notre plateforme vers un modèle Data Mesh, en assurant que les données sont traitées comme des produits de haute qualité.
- Cloud AWS : Gérer les services de stockage et de calcul sur notre infrastructure AWS (notamment S3).
- Qualité & Robustesse : Assurer la fiabilité du code par l'implémentation rigoureuse de tests unitaires et des mécanismes de contrôle de qualité des données., Les collaborateurs, tous issus de grandes écoles, incarnent au quotidien les valeurs d'Excellence, de Partage et d'Engagement. Ils associent savoir-faire technique, méthodologie et passion et mettent leurs compétences au service de missions et projets au sein de grands groupes français.
MP DATA accompagne ses clients sur toute la chaine au travers de 3 pôles d'expertise : Conseil et Stratégie, Infrastructure & CloudOPS, Data Science.
Chez MP DATA, les équipes commerciales cherchent des missions en fonction des envies des collaborateurs et non pas l'inverse. Les consultants sont accompagnés dans tous leurs projets, de la mobilité géographique, au changement de secteur d'activité en passant par le développement de nouvelles compétences. Rejoindre MP DATA, c'est la garantie de travailler sur des sujets passionnants avec un cadre technique fort., Des projets techniques exigeants au coeur des environnements industriels.
- Une culture orientée expertise, excellence technique, bienveillance et autonomie.
- Des perspectives d'évolution rapides selon vos envies (expertise, lead technique, pilotage...).
- Un environnement flexible, dynamique, avec une équipe soudée et passionnée.
- Une implantation locale forte à Toulouse, combinée à une vision innovante dans la Data.
Processus :
1 - Prise de Contact (15min par téléphone)
2 - Entretien avec un Ingénieur d'affaires (45min)
3 - Test technique
4 - Entretien Technique (1h)
5 - Visite des locaux
Requirements
Maîtrise de PySpark : Capacité prouvée à écrire du code Spark optimisé pour le traitement de gros volumes de données.
- Expertise en Orchestration : Expérience significative avec Apache Airflow.
- Expérience Cloud : Bonne connaissance des services de base d'Amazon Web Services (AWS), en particulier S3.
- Fondations Solides : Excellente maîtrise de Python et de SQL.
Ce qui fera la Différence :
- Vous comprenez et adhérez aux principes de l'architecture Data Mesh et avez idéalement déjà travaillé dans un environnement similaire.
- Vous êtes rigoureux et le concept de Tests Unitaires est une seconde nature pour vous, garantissant des pipelines solides et maintenables.
- Vous êtes autonome, proactif(ve) et à l'aise pour travailler sur une dataplatforme interne développée sur mesure.