AI Infrastructure / Platform Engineer - GPU compute
Role details
Job location
Tech stack
Job description
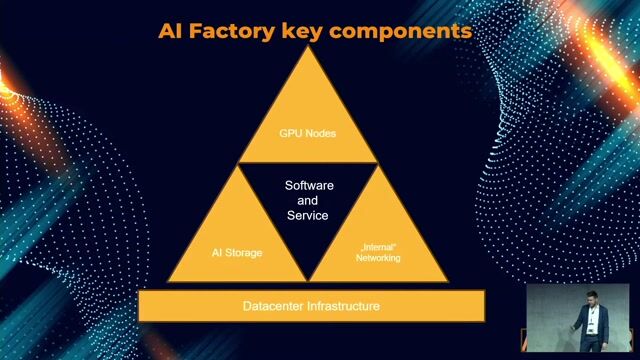
We are seeking an AI Infrastructure / Platform Engineer to join our team building and operatinglarge-scale GPUcomputeinfrastructure that powers AI and ML workloads. The ideal candidate should be passionate about software engineering andpossessleadership skills to independently deliver on multiple projects. They should be able to communicate effectively and work optimally with their peers within our larger organization., * Build and extend platform capabilities to enable different classes ofworkloads(e.g.,Large-scale AI training, inferencingetc).
-
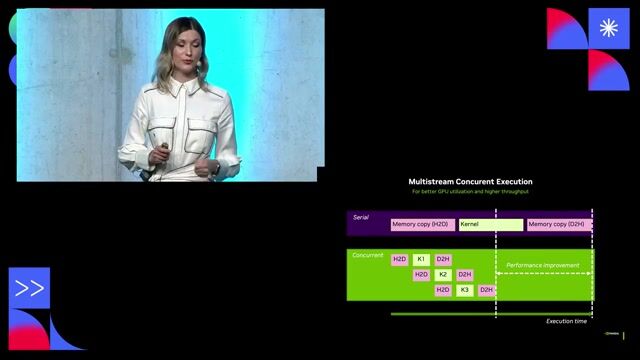
Design andoperatescalable orchestration systems using Kubernetes across both on-prem and multi-cloud environments.
-
Develop platform features such as pre-flight health checks, job statusmonitoringand post-mortem analysis.
-
Partner with development teams to extend the GPU developer platform with features, APIs, templates, and self-service workflows that streamline job orchestration and environment management.
-
Applyexpertisein storage and networking to design and integrate CSI drivers, persistent volumes, and network policies that enable high-performance GPU workloads., AMD may use Artificial Intelligence to help screen, assess or select applicants for this position. AMD's "Responsible AI Policy" is available here.
Requirements
-
Experience in Platform, Infrastructure, DevOps Engineering.
-
Deep hands-on experience with Kubernetes and container orchestration at scale.
-
Proven ability to design and deliver platform features that serve internal customers or developer teams
-
Experience building developer-facing platforms or internal developer portals (e.g. Customworkflow tooling)., * Hands-on experience in storage or network engineering within Kubernetes environments (e.g., CSI drivers, dynamic provisioning, CNI plugins, or network policy).
-
Experience with Infrastructure as Code tools like Terraform.
-
Background in HPC,Slurm, or GPU-basedcomputesystems for ML/AI workloads.
-
Practical experience with monitoring and observability tools (Prometheus, Grafana, Loki, etc.).
-
Understanding of machine learning frameworks (PyTorch,vLLM,SGLang, etc.).
-
High performance network and IB/RDMA tuning., * Bachelor's or master's degree in computer science, computer engineering, electrical engineering, or equivalent.
Benefits & conditions
$192,000.00/Yr.-$288,000.00/Yr.