Streaming AI Responses in Real-Time with SSE in Next.js & NestJS
Are long AI wait times hurting your app? Learn how Server-Sent Events deliver responses in under 200 milliseconds, boosting retention and cutting costs.
#1about 4 minutes
Why streaming AI responses improves user experience
Streaming AI text token-by-token significantly improves user retention and engagement compared to showing a loading screen.
#2about 2 minutes
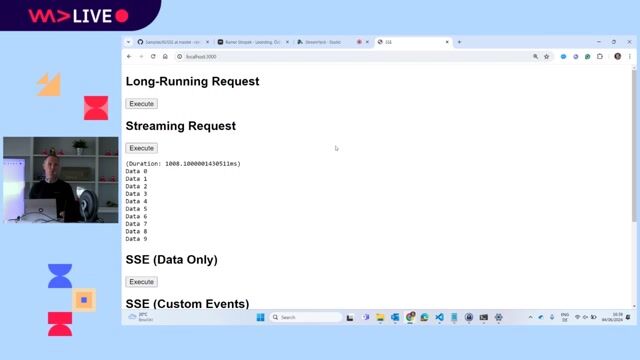
Comparing SSE, WebSockets, and polling for real-time data
Server-Sent Events (SSE) offer a lightweight, unidirectional alternative to WebSockets for pushing data, consuming half the memory per connection.
#3about 4 minutes
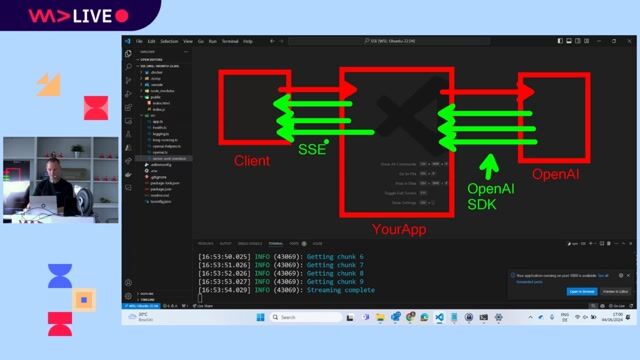
A full-stack architecture for streaming AI responses
The frontend uses the browser's EventSource API to subscribe to a NestJS backend endpoint that streams data from an AI provider.
#4about 2 minutes
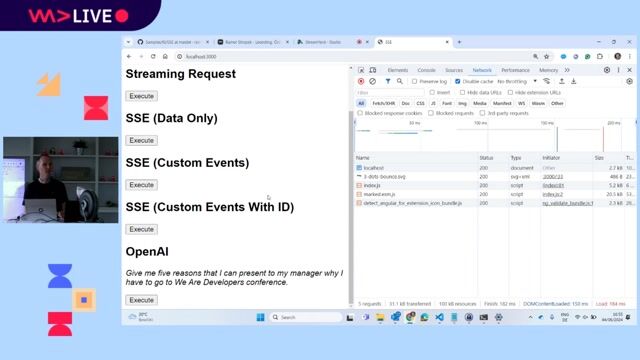
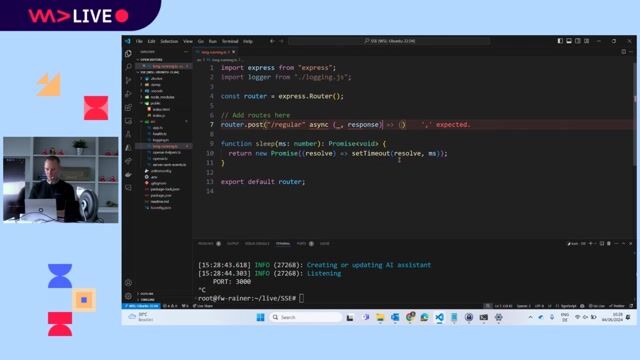
Implementing an SSE endpoint in NestJS for AI streaming
Set the `text/event-stream` content type and use a loop to push data chunks received from the OpenAI or Gemini streaming API to the client.
#5about 2 minutes
Consuming SSE streams in Next.js with EventSource
Use the native `EventSource` object to connect to the streaming endpoint and append incoming data to the component's state for a typewriter effect.
#6about 5 minutes
Using SSE for notifications and real-time file sharing
A code demonstration shows how to manage multiple client connections and push different event types, such as notifications or file data, to all subscribers.
#7about 2 minutes
Preparing an SSE implementation for production environments
Ensure reliability in production by adding authentication guards, rate limiting, keep-alive messages, and configuring proxy buffering in Nginx.
#8about 2 minutes
Scaling SSE applications for thousands of concurrent users
For large-scale applications, progress from a simple load balancer to using Redis Streams for message queuing or a dedicated SSE hub infrastructure.
#9about 2 minutes
Comparing AI providers for optimal streaming performance
AI providers like Groq, Gemini, and OpenAI differ in their streaming approach, offering either token-by-token or chunk-by-chunk responses which impacts perceived speed.
#10about 3 minutes
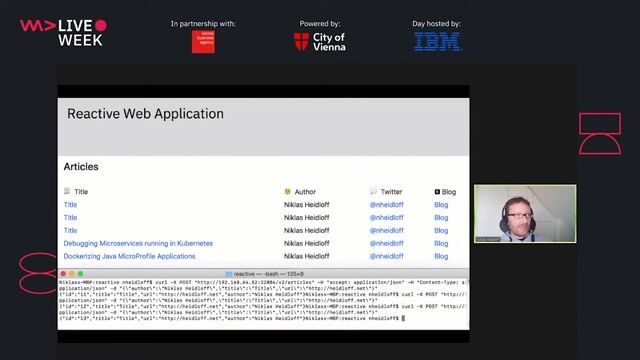
Syncing data from ChatGPT to multiple client applications
A custom GPT action can trigger a backend process that uses SSE to push new data in real-time to a user's browser extension, desktop, and mobile apps simultaneously.
#11about 1 minute
Understanding SSE limitations and its key benefits
Use SSE for unidirectional server-to-client data push, but choose other protocols like WebRTC for video or gRPC for microservices, to leverage its benefits of low latency and better user trust.
Related jobs
Jobs that call for the skills explored in this talk.
How to Turn Community Events Into a Powerful AI GTM Engine: The Daytona PlaybookWhen you first meet Marijan Cipcic, you might not expect a PhD historian to be helping build one of the fastest-growing AI developer communities in the world. But that unconventional background is exactly what makes his approach different.
Before joi...
Dev Digest 215: Agent Memory, JS2026, Googlebot Analysis & Canvas❤️HTMLInside last week’s Dev Digest 215 .
🗿 Make AI talk like a caveman
🧠 A guide to context engineering for LLMs
🤖 Simon Willison on agentic engineering
🔐 Axios supply chain attack post mortem
🛡️ Designing AI agents to resist prompt injection
🎨 HTML in c...
From learning to earning
Jobs that call for the skills explored in this talk.