.gif?w=720&auto=compress,format)
Welcome to this issue of the WeAreDevelopers Live Talk series. This article recaps an interesting talk by Bas Geerdink who gave advice on MLOps.
About the speaker:
Bas is a programmer, scientist, and IT manager. At ING, he is responsible for the Fast Data chapter within the Analytics department. His academic background is in Artificial Intelligence and Informatics. His research on reference architectures for big data solutions was published at the IEEE conference ICITST 2013. Bas has a background in software development, design, and architecture with a broad technical view from C++ to Prolog to Scala and is a Spark Certified Developer. He occasionally teaches programming courses and is a regular speaker at conferences and informal meetings.
Recently he spoke at the WeAreDevelopers Machine Learning Day.
Machine Learning
First of all, Bas wants to provide the audience with a broad overview of machine learning. He doesn’t want to go too much into detail as it is a very complicated subject and would go beyond the scope but since it’s the foundation of his talk, he wants to explain a bit.
Machine learning is divined into all kinds of different algorithms, learning methods, and technologies.
Basically, it is an application of AI that enables systems to learn and improve from experience without being explicitly programmed. This field focuses on developing computer programs that can access data and use it to learn for themselves. To achieve this learning process, you need to program a so-called neural network. These can be trained with given data sets to achieve tasks on their own, like for example image recognition.
But how do people “normally” do this? Typically, future data scientists learn in university (or online courses) learn notebook development with tools like jupyter. Bas thinks notebooks are a great technology as they are very easy to use as you have immediate feedback on how your code performs. This means you can write small pieces of code and run them in a cell and get instant visible results. So, it’s a good way to experiment with data, make small changes, and reflect on what has happened exactly. Hence these advantages the data science community adopted notebook development.
But that doesn’t signify that they are usable in a production environment because notebooks were not intended to work in that way.
Bas refers to an article called “Hidden Technical Debt in Machine Learning Systems” to show the broader picture. Look at this image taken from the said paper:
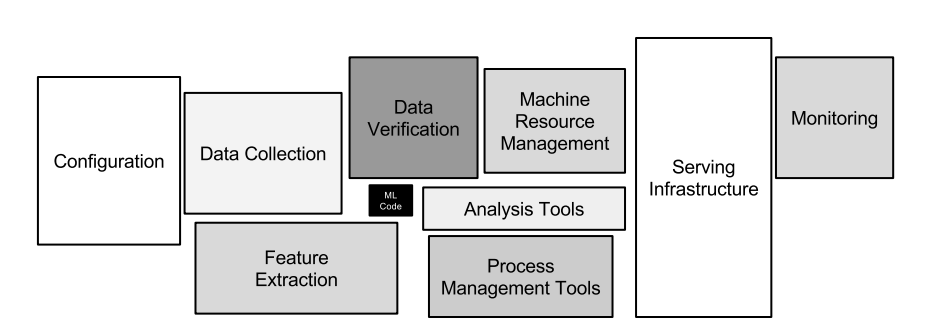
Here it becomes clear that the code (you might develop in a notebook) is only a small part of the whole system as there are a lot of other tools, technologies, and mechanisms around. So, Bas doesn’t want to talk about the small black box in the middle, rather he wants to talk about all the things that surround it.
MLOps to the Rescue
Bas wants to start with the mindset and culture you should employ. It’s not called MLOps for nothing, as it’s a continuation of DevOps.
Quick reminder: DevOps was invented about 10 years ago. Before that, it was very common for companies to have development organizations and development organizations and usually there was a big wall (metaphorically speaking) between them. So once developers had created something like a piece of software, they wanted to use in production they would throw it over the wall to the operations guys and these people were then responsible for maintaining it.
As that kind of thinking was not very efficient the idea came up to combine developers and operations in one team. They of course will still have their own specialty (developers writing code and operations do the configuration management) but they are in one team with one single shared responsibility: develop and maintain the software in production.
And MLOps is kind of the same but with a bit of extension because it adds machine learning as a third specialty apart from development and operations. This form spread more and more in the industry for the same reason DevOps was necessary: Data scientists usually worked beside the other teams and not directly with them.
The two main goals of MLOps are to add trust and speed. With continuous integration and delivery, you will gain trust in developing new models and putting them into production and therefore also increase the speed of it.
Best Practices in Machine Learning
A machine learning model is an algorithm (computer code) that takes input data (features) and produces a prediction (score). These models can be exported to a file, just like other software assets, and have a certain lifecycle of course.
It’s important to add metadata to your code including version, accuracy, feature importance, and documentation.
To prevent data drift, testing and monitoring your product is a necessity. Plan in time and work power to achieve this the right way.
Regarding monitoring: always look after both the technical (infrastructure) metrics and the business (performance) metrics. This way you can make sure that your model hasn’t diverged too much from the data that it was originally trained on.
And last but certainly not least: Keep on optimizing to improve business outcomes (prediction scores).
MLOps Architecture
Let’s move on to the more technical part of the talk: The architecture of the machine.
When you google how to do MLOps and what is the tooling that I need, you will get a lot of very detailed pictures that are heavily biased towards one or two vendors or technologies, etc.
But Bas wants to give an overview, like a reference picture, that captures everything.
To put a machine learning model in production you basically need two pipelines: real-time and batch.
The batch part is actually where you train the model. That’s always done in batches (hence the naming) as even if you apply something fancy like online learning, then your online learning mechanism will still be a batch job that runs every minute or so.
Normally what people would do in a company is they will capture data in a feature store, keep it there for a few months and then run a model retraining pipeline that teaches the model every week. This way you can export an artifact and store it in the model registry.
Once this model is available it can be used in real-time in a scoring pipeline. Bas here gives the example of the webshop of a big retail company. They all follow this pattern and are retrained with the data that is captured from the customers.
MLOps Tooling
Now Bas wants to do a dive into the tooling itself. Again, if you search online for MLOps tooling you will get something very complicated as there is such a big offer on utensils to use for this kind of work. And out of this big pot, you must make your pick. For this, you also need to know your own environment and what fits your culture and the needs of the team.
To make that process easier for you Bas provides some principles to follow.
First: Buy versus build. That’s the traditional discussion you will have in many companies. Some questions you might want to ask yourself regarding this are:
- Can we reuse existing components?
- How do things fit in the architecture?
- Do we want to work with vendors or the open-source community?
- The other point in the discussion is are we going with AutoML or will we do a custom approach?
Bas also provides some questions for you to make that decision:
- What culture fits my organization?
- What kind of people need to use the tooling?
- What kind of scale?
So these are the important choices you have to make before going with one of those tools or frameworks.
Further Tips
- By containerizing your business logic, it will be independent of infrastructure, testable, and scalable.
- Define your infrastructure as code to enable versioning, automated deployments, and terraform.
- Use a feature store. That is a database for reusable features including API, data quality checks etc.
- A machine learning model trainer or scorer can query the feature store in batch or real-time
Thank you for reading this article. If you are interested in hearing Bas himself you can do so by following this link: Free Developer Talks & Coding Tutorials | WeAreDevelopers.