Data Engineer
Role details
Job location
Tech stack
Job description
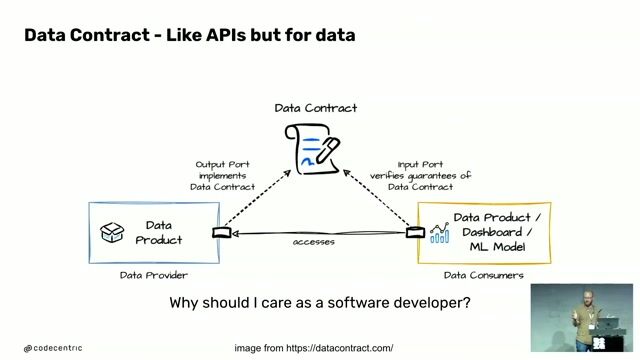
specific file formats and processing challenges. Collaborating closely with our Science teams to adapt their calculation models (which may come in Python, R, or .Net) so they can be validated, monitored, and scaled effectively within our production pipelines. Contributing to our DevOps culture by working closely with the Platform team. This includes managing infrastructure as code (Terraform) and building and maintaining our CI/CD pipelines in GitLab. Helping our organization on its journey to democratize data access for everyone. REQUIRED EXPERIENCE / SKILLS We are expanding the team and are open to hiring both mid-level and senior. This section is not a rigid checklist. We believe this role is a great fit if you bring: A strong foundation in Python as a primary language for data processing and backend development. Solid experience in data engineering: You have built and maintained data pipelines before and understand the fundamentals of data orchestration, validation, and processing.
Requirements
A collaborative, service-oriented mindset: You enjoy helping others and understand the value of building platforms that enable other teams (that "Team Topologies" spirit). A genuine interest in DevOps and infrastructure: You are comfortable working close to the metal and believe that teams should own their services, from code to deployment (CI/CD, IaC). A pragmatic approach to technology: You understand that we must support existing codebases (like .Net or R) while building the future in Python. Professional fluency: You must be fluent in Spanish and English The following skills are definitely not required, but they are great complements to our team. Direct experience with Airflow and/or Kubernetes. Familiarity with the Azure cloud ecosystem. Previous exposure to geospatial data and its specific libraries or formats. Experience with Infrastructure as Code tools like Terraform or CI/CD systems like GitLab CI. An interest in emerging data platform technologies, such as Apache Iceberg. EDUCATION Education or certifications in Computer Science, Computer Engineering, Systems Administration, Software Development, or similar. English certifications will be valued. BENEFITS Competitive annual salary. An annual bonus based on individual and company performance. Flexible working hours. Possibility of remote work. Are you interested? Apply here:https://technosylva.bamboohr.com/careers/156 At Technosylva, we value diverse experiences and skills, and we understand that each career path is unique. Therefore, we encourage all individuals who believe they meet most of the requirements and are interested in growing and contributing in the role to apply. DISCLAIMER The final salary and benefits depend on a variety of factors, including location, experience, training, qualifications, and market demands. INCLUSION COMMITMENT Technosylva is an equal opportunity employer. We are committed to creating an inclusive environment where diverse perspectives contribute to better solutions.