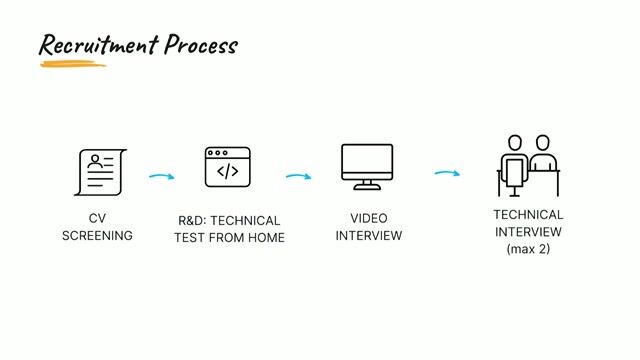
Référent Big Data (H/F)
Role details
Job location
Tech stack
Job description
Votre mission : construire, fiabiliser et faire évoluer l?infrastructure Data tout en accompagnant les équipes techniques vers les nouveaux standards.
VOS RESPONSABILITES PRINCIPALES: Accompagner la migration des environnements Hadoop / Cloudera on-prem vers le cloud public.
Concevoir et industrialiser les pipelines de données batch et streaming (Spark, Kafka, Flink).
Déployer et maintenir une plateforme Data performante et robuste (Data Lake / Data Mesh).
Agir en référent technique : partage de bonnes pratiques, revue de code, accompagnement des équipes.
Assurer le suivi en production : monitoring, automatisation, amélioration continue.
Requirements
Profil candidat:EXPERIENCE: +7 ans d?expérience en ingénierie Big Data sur des environnements complexes et critiques.
Solide expérience des écosystèmes distribués (Cloudera, Hadoop, Spark).
Participation à des projets de migration vers le cloud (AWS ou GCP).
Double compétence Build & Run (architecture, déploiement, supervision).
Habitude de contextes grands comptes, multi-projets et à forte volumétrie.
Capacité à agir comme référent technique ou lead (coaching, cadrage, validation technique).
COMPETENCES TECHNIQUES: Big Data & Data Engineering : Cloudera, Kafka, Spark, Flink, NiFi, Airflow, Trino / Starburst.
Cloud : AWS (EMR, MSK, S3, Glue) ou GCP (DataProc, BigQuery, Dataflow, Cloud Storage).
Infrastructure & IaC : Linux (niveau admin), Kubernetes, Terraform.
CI/CD & automatisation : GitLab CI, ArgoCD, GitOps, Helm.
Langages : Scala, Java, Python.
Monitoring & observabilité : Prometheus, Grafana, ELK, AlertManager.
Méthodologies : Agile / Scrum, ITIL v4 (CERTIFICATION ITIL 4 OBLIGATOIRE).
Langue : Anglais professionnel indispensable.