Efficient deployment and inference of GPU-accelerated LLMs
What if you could deploy a fully optimized LLM with a single command? See how NVIDIA NIM abstracts away the complexity of self-hosting for massive performance gains.
#1about 2 minutes
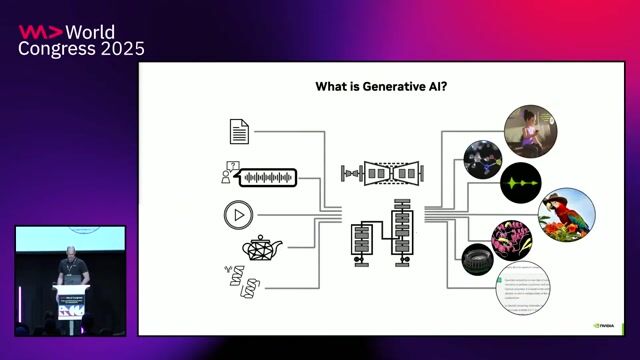
The evolution of generative AI from experimentation to production
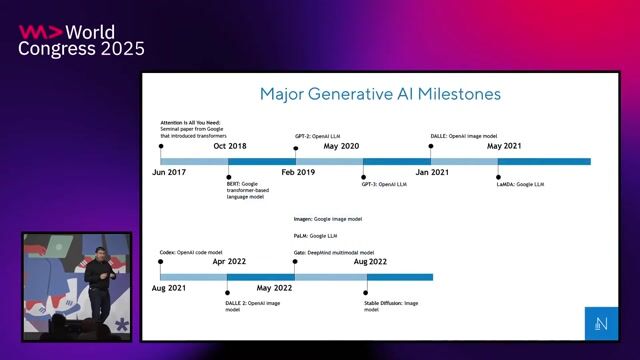
Generative AI has rapidly moved from experimentation with models like Llama and Mistral to production-ready applications in 2024.
#2about 3 minutes
Comparing managed AI services with the DIY approach
Managed services offer ease of use but limited control, while a do-it-yourself approach provides full control but introduces significant complexity.
#3about 4 minutes
Introducing NVIDIA NIM for simplified LLM deployment
NVIDIA Inference Microservices (NIM) provide a containerized, OpenAI-compatible solution for deploying models anywhere with enterprise support.
#4about 2 minutes
Boosting inference throughput with lower precision quantization
Using lower precision formats like FP8 dramatically increases model inference throughput, providing more performance for the same hardware investment.
#5about 2 minutes
Overview of the NVIDIA AI Enterprise software platform
The NVIDIA AI Enterprise platform is a cloud-native software stack that abstracts away low-level complexities like CUDA to streamline AI pipeline development.
#6about 2 minutes
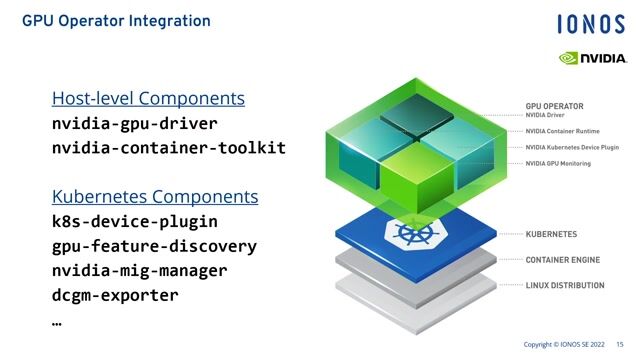
A look inside the NIM container architecture
NIM containers bundle optimized inference tools like TensorRT-LLM and Triton Inference Server to accelerate models on specific GPU hardware.
#7about 3 minutes
How to run and interact with a NIM container
A NIM container can be launched with a simple Docker command, automatically discovering hardware and exposing OpenAI-compatible API endpoints for interaction.
#8about 2 minutes
Efficiently serving custom models with LoRA adapters
NIM enables serving multiple customized LoRA adapters on a single base model simultaneously, saving memory while providing distinct model endpoints.
#9about 3 minutes
How NIM automatically handles hardware and model optimization
NIM simplifies deployment by automatically selecting the best pre-compiled model based on the detected GPU architecture and user preference for latency or throughput.
Related jobs
Jobs that call for the skills explored in this talk.
Dev Digest 157: CUDA in Python, Gemini Code Assist and Back-dooring LLMsInside last week’s Dev Digest 157 .
🕹️ Pong in 240 browser tabs
👩💻 Gemini Code Assist free for 180k code completions a month
📰 AI is bad at coding and summarising the news
🕵️ Private GitHub repos show up in AI chats
🐍 CUDA for Python developers
🖥️ ...
Benedikt Bischof
MLOps And AI Driven DevelopmentWelcome to this issue of the WeAreDevelopers Dev Talk Recap series. This article recaps an interesting talk by Natalie Pistunovic who spoke about the development of AI and MLOps. What you will learn:How the concept of AI became an academic field and ...
Daniel Cranney
Panel Discussion: Responsible AI in Practice - Real-World Examples and ChallengesIntroductionIn the ever-evolving landscape of artificial intelligence, the concept of "responsible AI" has emerged as a cornerstone for ethical and practical AI implementation. During the WWC24 Panel discussion, three eminent experts—Mina, Bjorn Brin...








.gif?w=240&auto=compress,format)


