Training large language models is a networking problem, not a compute problem. Learn how to keep thousands of GPUs from sitting idle.
#1about 2 minutes
Introduction to large-scale AI infrastructure challenges
An overview of the topics to be covered, from the progress of generative AI to the compute requirements for training and inference.
#2about 4 minutes
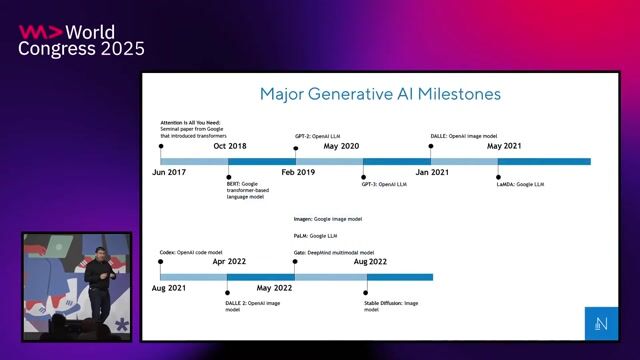
Understanding the fundamental shift to generative AI
Generative AI creates novel content, moving beyond prediction to unlock new use cases in coding, content creation, and customer experience.
#3about 6 minutes
Using NVIDIA NIMs and blueprints to deploy models
NVIDIA Inference Microservices (NIMs) and blueprints provide pre-packaged, optimized containers to quickly deploy models for tasks like retrieval-augmented generation (RAG).
#4about 4 minutes
An overview of the AI model development lifecycle
Building a production-ready model involves a multi-stage process including data curation, distributed training, alignment, optimized inference, and implementing guardrails.
#5about 6 minutes
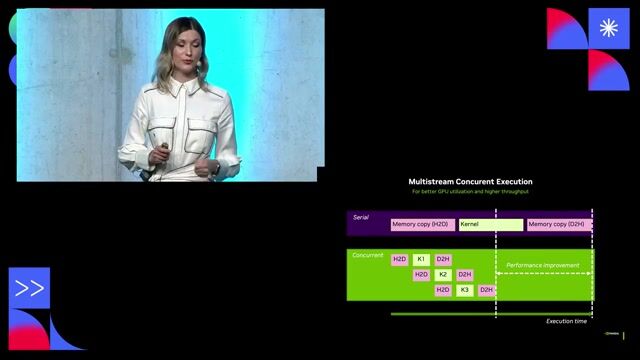
Understanding parallelism techniques for distributed AI training
Training massive models requires splitting them across thousands of GPUs using tensor, pipeline, and data parallelism to manage compute and communication.
#6about 2 minutes
The scale of GPU compute for training and inference
Training large models like Llama requires millions of GPU hours, while inference for a single large model can demand a full multi-GPU server.
#7about 3 minutes
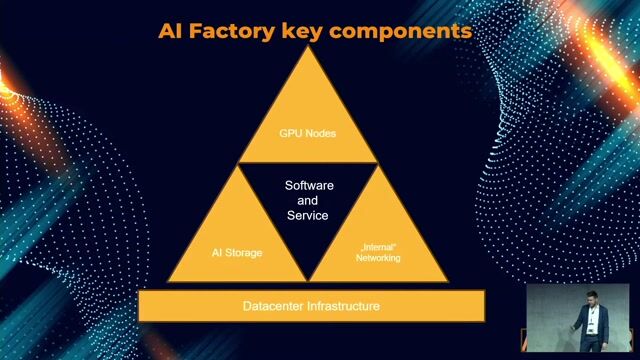
Key hardware and network design for AI infrastructure
Effective multi-node training depends on high-speed interconnects like NVLink and network architectures designed to minimize communication latency between GPUs.
#8about 3 minutes
Accessing global GPU capacity with DGX Cloud Lepton
NVIDIA's DGX Cloud Lepton is a marketplace connecting developers to a global network of cloud partners for scalable, on-demand GPU compute.
Related jobs
Jobs that call for the skills explored in this talk.
Stephan Gillich - Bringing AI EverywhereIn the ever-evolving world of technology, AI continues to be the frontier for innovation and transformation. Stephan Gillich, from the AI Center of Excellence at Intel, dove into the subject in a recent session titled "Bringing AI Everywhere," sheddi...
Krissy Davis
The Best Large Language Models on The MarketLarge language models are sophisticated programs that enable machines to comprehend and generate human-like text. They have been the foundation of natural language processing for almost a decade. Although generative AI has only recently gained popula...
From learning to earning
Jobs that call for the skills explored in this talk.















.png?w=240&auto=compress,format)
