Turn five minutes of data processing into one second. This talk shows you how to accelerate your Python code on GPUs.
#1about 1 minute
The evolution of GPUs from graphics to AI computing
GPUs transitioned from rendering graphics to becoming essential for general-purpose parallel computing and accelerating the deep learning revolution.
#2about 2 minutes
Why GPU acceleration surpasses traditional CPU performance
The plateauing of single-core CPU performance contrasts with the continued exponential growth of GPU parallel processing power, driving the adoption of accelerated computing.
#3about 2 minutes
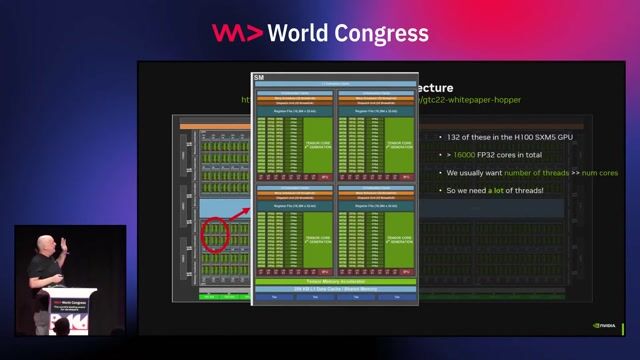
Understanding the CUDA software ecosystem stack
The CUDA platform provides a layered ecosystem, allowing developers to use high-level applications, libraries, or program GPUs directly depending on their needs.
#4about 3 minutes
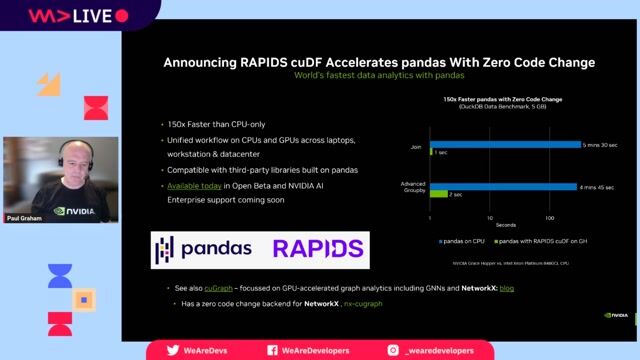
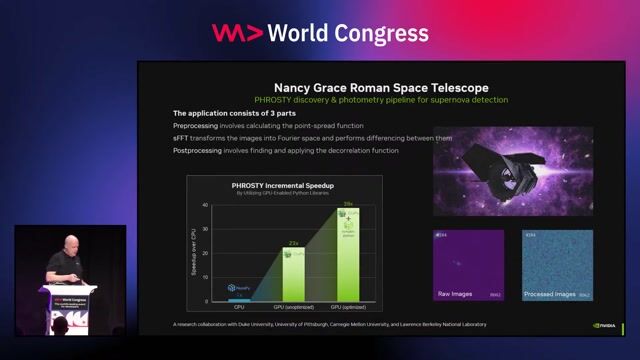
Using high-level frameworks like RAPIDS for data science
Frameworks like RAPIDS provide GPU-accelerated, API-compatible replacements for popular data science libraries like Pandas and Scikit-learn, often requiring no code changes.
#5about 2 minutes
Accelerating deep learning with cuDNN and Cutlass
The cuDNN library provides optimized deep learning primitives for frameworks like PyTorch, while Cutlass offers direct programming access to Tensor Cores for custom operations.
#6about 2 minutes
A spectrum of approaches for programming GPUs in Python
Developers can choose from a spectrum of GPU programming approaches in Python, ranging from simple drop-in libraries to directive-based compilers and direct API control.
#7about 2 minutes
Drop-in libraries like CuPy and cuNumeric for easy acceleration
Libraries like CuPy and cuNumeric offer NumPy-compatible APIs that enable GPU acceleration and multi-node scaling with just a single import statement change.
#8about 3 minutes
Gaining more control with the Numba JIT compiler
Numba acts as a just-in-time compiler that translates Python functions into optimized GPU code using simple decorators for either automatic vectorization or explicit kernel writing.
#9about 1 minute
Achieving maximum flexibility with PyCUDA and C kernels
PyCUDA provides the lowest-level access to the GPU from Python, allowing developers to write and execute raw CUDA C kernels for complete control over hardware features.
#10about 2 minutes
Profiling and debugging GPU-accelerated Python code
NVIDIA provides a full suite of Python-enabled developer tools for performance analysis, including Insight Systems for system-level profiling and Insight Compute for kernel-level optimization.
#11about 2 minutes
Accessing software, models, and training resources
NVIDIA offers extensive resources including the NGC catalog for containerized software, pre-trained models, and the Deep Learning Institute for self-paced training courses.
Related jobs
Jobs that call for the skills explored in this talk.
What’s the latest in NVIDIA CUDA PythonPython and NVIDIA CUDA have long been friends. Over the last year, NVIDIA teams are working to improve the Pythonista’s experience. This means a top-to-bottom update to the CUDA Platform is fueling the GenAI movement, e.g. llama3, gpt and nemo. These...
Daniel Cranney
Dev Digest 157: CUDA in Python, Gemini Code Assist and Back-dooring LLMsInside last week’s Dev Digest 157 .
🕹️ Pong in 240 browser tabs
👩💻 Gemini Code Assist free for 180k code completions a month
📰 AI is bad at coding and summarising the news
🕵️ Private GitHub repos show up in AI chats
🐍 CUDA for Python developers
🖥️ ...
Chris Heilmann
All the videos of Halfstack London 2024!Last month was Halfstack London, a conference about the web, JavaScript and half a dozen other things. We were there to deliver a talk, but also to record all the sessions and we're happy to share them with you. It took a bit as we had to wait for th...
Christina Schaireiter
5 Reasons Why Attending Conferences in 2026 Matters More Than You ThinkIt’s 2026, and the “remote vs. office” debate has finally settled into a high-tech hybrid reality. While we’ve perfected the art of shipping production-grade code from decentralized hubs and home setups, something shifted. We realized that while AI c...
From learning to earning
Jobs that call for the skills explored in this talk.