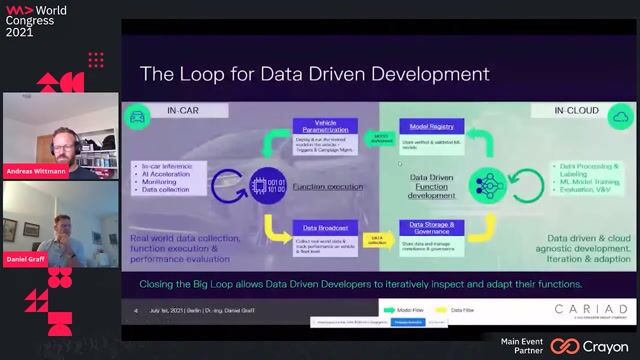
Intelligent Data Selection for Continual Learning of AI Functions
What if the key to better AI isn't the data you collect, but the vast amount of data you discard? This talk explores intelligent on-device data selection.
#1about 3 minutes
Understanding the core use cases for data selection
Data selection is crucial for creating diverse datasets, enabling active learning, detecting corner cases, and building new AI functions.
#2about 4 minutes
Comparing data sources for machine learning models
Data can be sourced from data lakes with heavy compute, targeted test fleets, or the vast customer fleet which offers real-world scenarios but has limited compute.
#3about 2 minutes
Identifying informative data in long-tail distributions
Informative data lies in the long tail of the data distribution, including rare scenarios, weak sensor signals, and atypical class distributions.
#4about 3 minutes
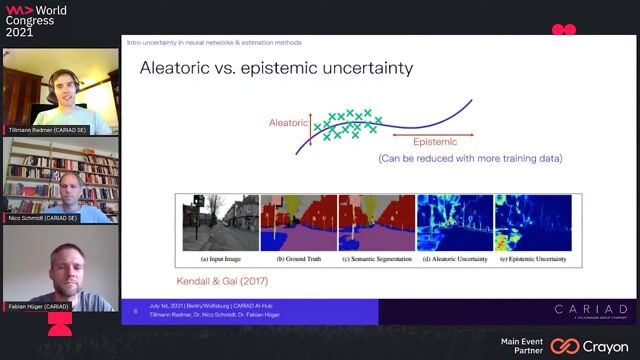
Overview of methods for intelligent data selection
Key methods for selecting valuable data include uncertainty estimation, temporal analysis of predictions, anomaly detection, and using model ensembles.
#5about 3 minutes
Using softmax uncertainty for traffic light detection
An uncertainty trigger aggregates softmax scores from a traffic light detection model to identify and record challenging images like false positives or distant objects.
#6about 4 minutes
Evaluating model improvements from selected data
Proper model evaluation requires testing against not just random data but also corner-case datasets to prevent performance regressions in specific scenarios.
#7about 5 minutes
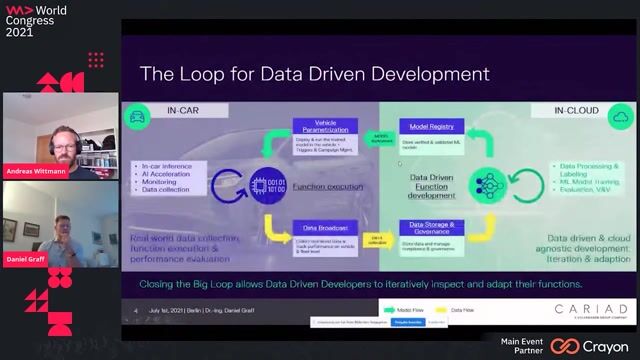
Deploying data selection triggers to the vehicle fleet
An in-vehicle module called "Instinct" filters data streams in real-time, enabling continual learning by collecting data from new regions to expand a model's operational domain.
#8about 5 minutes
Building a universal data selection framework
A universal framework uses a plugin architecture to support various trigger types and treats perception functions as black boxes by using a framework-independent format like ONNX.
#9about 21 minutes
Overcoming challenges in automotive software deployment
Deploying data science code to vehicles requires bridging Python and C++, ensuring high code quality, and maintaining full traceability from requirements to artifacts.
Related jobs
Jobs that call for the skills explored in this talk.
Panel Discussion: Responsible AI in Practice - Real-World Examples and ChallengesIntroductionIn the ever-evolving landscape of artificial intelligence, the concept of "responsible AI" has emerged as a cornerstone for ethical and practical AI implementation. During the WWC24 Panel discussion, three eminent experts—Mina, Bjorn Brin...
Daniel Cranney
GitHub's Copilot Ads and Opt-out for AI Training DataOur newsletter - The Dev Digest - is packed with links to all kinds of tech content, but we just can’t cover everything. That’s why we put together the Overflow, where we share some of our favourites in bonus posts and videos, and this time we’re ta...
Chris Heilmann
Exploring AI: Opportunities and Risks for DevelopersIn today's rapidly evolving tech landscape, the integration of Artificial Intelligence (AI) in development presents both exciting opportunities and notable risks. This dynamic was the focus of a recent panel discussion featuring industry experts Kent...