When is retrieval-augmented generation not enough? Learn the multi-stage process for deeply embedding new knowledge into an open-source LLM.
#1about 4 minutes
Understanding the LLM training pipeline and knowledge gaps
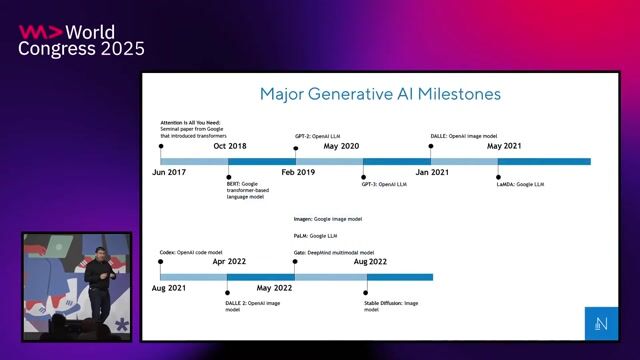
LLMs are trained through pre-training and alignment, but require new knowledge to stay current, adapt to specific domains, and acquire new skills.
#2about 5 minutes
Adding domain knowledge with continued pre-training
Continued pre-training adapts a foundation model to a specific domain by training it further on specialized, unlabeled data using self-supervised learning.
#3about 6 minutes
Developing skills and reasoning with supervised fine-tuning
Supervised fine-tuning uses instruction-based datasets to teach models specific tasks, chat capabilities, and complex reasoning through techniques like chain of thought.
#4about 8 minutes
Aligning models with human preferences using reinforcement learning
Preference alignment refines model behavior using reinforcement learning, evolving from complex RLHF with reward models to simpler methods like DPO.
#5about 2 minutes
Using frameworks like NeMo RL to simplify model alignment
Frameworks like the open-source NeMo RL abstract away the complexity of implementing advanced alignment algorithms like reinforcement learning.
Related jobs
Jobs that call for the skills explored in this talk.
What Are Large Language Models?Developers and writers can finally agree on one thing: Large Language Models, the subset of AIs that drive ChatGPT and its competitors, are stunning tech creations. Developers enjoying the likes of GitHub Copilot know the feeling: this new kind of te...
Krissy Davis
The Best Large Language Models on The MarketLarge language models are sophisticated programs that enable machines to comprehend and generate human-like text. They have been the foundation of natural language processing for almost a decade. Although generative AI has only recently gained popula...
Panel Discussion: Responsible AI in Practice - Real-World Examples and ChallengesIntroductionIn the ever-evolving landscape of artificial intelligence, the concept of "responsible AI" has emerged as a cornerstone for ethical and practical AI implementation. During the WWC24 Panel discussion, three eminent experts—Mina, Bjorn Brin...
From learning to earning
Jobs that call for the skills explored in this talk.









.png?w=240&auto=compress,format)
.png?w=240&auto=compress,format)


